5月14日(土)に「第3回 MongoDB 勉強会 in Tokyo 」が開催されました。今回の勉強会参加登録は100人を超え、前回 以上の人に足を運んでいただきました。本稿では、今回の勉強会をレポートします。
なお、本勉強会の運営はフューチャーアーキテクト株式会社 様の全面協力によって支えられました。 @understeer さん、@uorat さん、@ixixi さんをはじめとしたスタッフの皆さんにも運営協力いただきました。お礼申し上げます。
会場風景。広い会場もあっという間に一杯になりました。
当日の発表
今回のタイムテーブルは次のとおりです。機能と仕組みの紹介からPHPへの応用の話、クエリチューニング、実サービスへの適用と注意点まで、多岐にわたる内容が発表されました。
@doryokujin「MongoDB全機能解説(1)」
筆者(@doryokujin )より、MongoDBの機能についての解説を行いました。すべてを一度に解説するのは無理があったため、今回は前編として以下の内容を話しました。本発表の目的は、機能の単純なチュートリアルというよりも、その機能を使う上での注意点をしっかりと理解してもらうことにありました。MongoDBにはあまり知られていない機能や振る舞いをたくさん持っています。それを知っていることが、これからの使用に当たって大きな助けとなるはずです。
1. MongoDBの構成
MongoDBは1つのデータベースに複数のコレクションを持ちます(MySQLでいうテーブル) 。その各コレクションがたくさんのドキュメントを保存しています。MongoDBの格納するデータの単位はドキュメントと呼ばれるもので、JSON形式になっています(内部ではBSON形式で保持されます) 。MongoDBを稼動させるためには mongodサーバーをまず起動しないといけません。このようなMongoDBを構成する要素を「サーバー」「 データベース」「 コレクション」にわけてそれぞれを紹介しました。
特に特殊なコレクション、「 Capped Collection」の特徴に興味を持ってくれた人が多かったのが印象的でした。Capped Collectionは固定サイズのコレクションで、サイズを超えるデータが入ってくる場合には最も古いデータを順に削除して挿入していきます。また、インデックスを作成しない限り、ファイルシステムにせまるほどの高速なWriteを行ってくれます。データがディスクを溢れる心配がない、高速なWrite、これらの特徴を活かしてログ集約ストレージや複雑なオブジェクトのキャッシュ機構として用いることができます。Capped Collectionについてはまた機会があれば紹介したいと思います。
2. Insertとその周辺
わざわざinsertを改めて取り上げたのは、insert処理については注意してほしい点がたくさんあったからです。
まずMongoDBを各種言語ドライバで使用する場合、基本的にinsert処理は"fire and forget"と呼ばれ、1回ごとの書き込みの成功を確認することなく次の処理へ進む動作になっています。これはいくつかのinsert処理が失敗しても気づかない場合があることを示しています。各種の統計計算を行うためのデータベースとして活用している場合はまだしも、決済系やユーザーの登録情報を保持する場合には一部のデータの欠損なんていうものは許されません。毎回の書き込み成功を確認するためのgetLastError()コマンドの重要性を述べた後、書き込みの安全性に関する機能:fsyncやjournalingについて説明しました。ちなみにMongoShellからのinsertコマンドはすべて毎回の書き込みの成功の有無を確認しています。
3. Query
MongoDBは非常に豊富なクエリを備えており、ドキュメントのあらゆるキーに対する要素に対して様々な条件で検索(findコマンド)をおこなうことができます。例えばある範囲内のデータを抽出するためのクエリ、特定の要素集合を(すべて/1つでも)含む配列を持つデータを抽出するためのクエリ、などです。
主要な注意点として、キーが入れ子になったフィールド(例えば "name: { firstname: Takahiro, lastname: Inoue }" )に対するクエリの記述は「Dot Notation」と「Sub Object」と呼ばれるものがあります。後者の場合は記述順序や数に依存するため、意図した結果を得ることができない可能性があることを紹介しました。
4. Update
Updateに関しても、特定のキーの値(数値)に指定した数だけインクリメントするコマンドや配列に要素を追加、削除するコマンドなど、こちらも非常に多くの機能を有しています。また、Update後にもドキュメントのサイズが変わらない場合には"In-Place Update"と呼ばれる非常に高速なupdateになります。
逆にサイズが大きく変わる場合には現在の保存領域には収まらないので領域の移動が行われます。その際はその移動の分だけ時間がかかるばかりか、移動前と移動後の2回重複してデータを取ってきてしまう可能性もあります。それに対しての対処法としてsnapshot()コマンドを使用することなどを挙げました。また、1回のコマンドで複数のドキュメントに更新が与えられる場合には、更新中に他の動作が介入しないように$atmicコマンドでロックをかける必要があることなどの注意点を述べました。
5. Index
MongoDBはドキュメントのあらゆるキーに対して(B-Tree)インデックスを作成することができます。これと豊富なクエリと併せて高速かつ柔軟なデータの取得を容易にしてくれます。ただし、MongoDBのindexは他に比べてindex sizeが大きくなりがちで、また、writeパフォーマンスにも影響を与えること、順序依存の問題などで必ずしもそのインデックスが使用されているとは限らないこと、またそれを調べるためにexplain()コマンドがあること等について触れました。
6. Replication
Master-SlaveとReplica Setsのうち、後者について詳しく説明しました。特に、細かな設定方法は割愛し、フェイルオーバー時の挙動などについて紹介しました(このあたりの話は普通に使っている限り、なかなか知ることのできない部分ですので、基礎を飛ばしました) 。Replicationについては、もう一回ほど機会を設けて実際にフェールオーバーを確認してもらうなどの実演を交えて紹介したいと思います。
MongoDBは特に海外においては非常に多くの企業がプロダクションとして導入しています。日本でも導入事例が増えてくることを目標に活動を進めていきたいと思います。
@bibrosさん「ソーシャルアプリのプロトタイプ制作にMongoDBを活用」
@bibrost さんより、ソーシャルアプリのプロトタイプの制作を用途として"MongoDBを活用しましょう"という趣旨の発表がなされました。
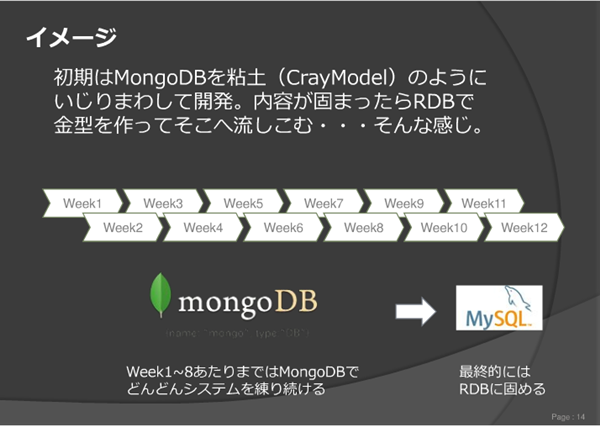
ソーシャルアプリなどの現場では初期段階でスキーマを定義するのは難しく、途中のレビューで変更が多々加えられてしまうので効率が良くないと指摘。そこで、最後RDBなどで実装することは決まっている場合でも、プロトタイプ段階ではスキーマフリーなMongoDBを活用して行き、ある程度スキーマが固まった時点でRDBへマイグレーションを行なってはどうか、というアイデアが紹介されました。つまり、MongoDBは粘土であり、様々に姿形を変えながら最後はRDBという金型に流し込むイメージです。
この話には、筆者を含め非常に多くの方が頷いている様子でした。あくまで最終的にはRDBを採用するにしても、その過程の段階ではMongoDBを活用するというのは非常に理にかなった使い方のように見えました。もちろん、いつMongoからRDBへの以降を決めるか、その際のマイグレーションをどううまくやるかの課題はありますが、それでも試して見る価値はありそうですね。
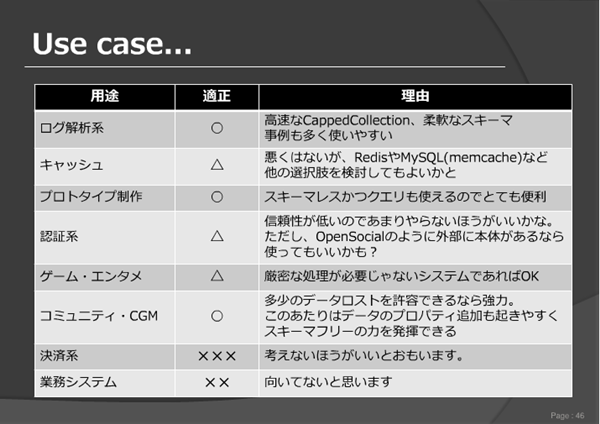
また、具体的にRestインターフェースであるsleepy.mongooseとPHPを利用した具体的なコード例も示されました。最後に、MongoDBのユースケースが紹介されました。これは、非常に的を得た図であるように思います。
筆者の話でもありましたが、高性能を維持する代わりに書き込みの欠損が生じるなど、多くの信頼性の問題を含むMongoDBですので、決済系やユーザーの重要な情報を保持する場合には今のところあまり向いていません。逆にキャッシュのように多少のデータロストが許される場合や、RDBやテキストなどにデータのマスターが別にあり、再現性のあるアクセスログなどのデータに対してはMongoDBはその柔軟性を活かして活躍できるという話でした。これについても、非常に多くの方が納得しておられました。
全体の感想
実際のWeb開発の現場の視点から述べていただき、非常に多くの気づきが得られました。現場においてMongoDBをどう使用するべきか、という今回の主要テーマは今後MongoDBを導入しようと考えられている方にとっては大きな参考となる内容でした。僕としては「MongoDBは粘土であり、RDBは金型」という表現が非常に気に入りました。
最後に本レポートとは関係ありませんが、@bibrost さんのブログエントリ「モテるMongoDB女子力を磨くための4つの心得 」は秀逸ですので、あわせてご覧ください。
@matsuou1さん「MongoDBチューニング〜スロークエリ撲滅までの道筋〜」
@matsuou1 さんより、MongoDBのクエリチューニングという、世界でもまだ紹介事例の少ない内容で発表していただきました。
MongoDBのクエリチューニングについて実行計画と、それに使用するコマンドについて詳しく紹介されました。このあたりの話は本家MongoDBドキュメントでも記述が少ないところですので、非常に良く調べられたのだという印象を受けました。
実際、MongoDBのスロークエリ特定方法は以下の3つがあります。
slowmsコマンドラインオプションをつけて起動する
db.setProfilingLevel(level,slowms)コマンドによって設定する
実行中のクエリを実際に確認する
これらの特定方法の基本的な使い方を丁寧に説明されました。それぞれの特定方法のメリット・デメリットがまとめられた表は非常にわかりやすかったです。
全体の感想
筆者自身もクエリチューニングをここまで本格に行ったことがなかったので、とても興味深く発表を聞かせていただきました。一見難しそうに見えるMongoDBのクエリチューニングですが、@matsuou1 さんのブログ からお言葉をお借りしますと、
私の結論としては、MongoDBではRDBMSとほぼ同じチューニングのアプローチ方法が取れます。RDBMSでチューニング経験がある人は、違和感なくやれると思います。
むしろ、JOINがない分、簡単かと。ただ、バックエンドで使う分には十分な方法が提供されているが、フロントエンドで使うには、実行回数が多い&ちょっとだけ遅いクエリを特定する方法が現状ないので、注意して見て行く必要があります。この辺りは今後のバージョンアップに期待しましょう。
とのことです。筆者も一度このスライドを参考にしながらスロークエリを調べてみたいと思います。
@ygenkiさん「MongoDBを使用したモバイルゲーム開発について」
@ygenki さんより、実サービスである、モバイルゲームへMongoDBを使用した際の使用感などについて発表していただきました。なお、現在のMongoDB勉強会では非公式にCA枠というものがあり、間違いなく日本で最もMongoDBを活用している企業であるCyber Agentの皆様に毎回発表をお願いしております。
さて、まず特筆すべきはモバイルゲームの内容です。その名も「東京Girls Snap 」 。
こんな楽しいゲームのバックグラウンドでMongoDBが活躍してくれていることを考えると、筆者は胸が熱くなります。4月にリリースされたということですが、そもそもMongoDBを使用することに決めた理由として以下の4つを挙げられていました。
スキーマレス
ドキュメントの階層構造
Replication & Sharding
MySQL + memcached からの移行
このうち、Shardingは実際のデータ量や使用用途を考えて現在のところは使用しておらず、負荷分散が必要になった時点で検討するという話です。
主に、あるユーザーのアルバムがどんどん増えていくデータに対しての利用において、ドキュメントが階層構造になっていることと非常に相性が良く、アルバムの追加も配列に対するupdateコマンド、$pushや$pullをうまく活用できることが紹介されていました。また、update処理を行う際に起こりやすいミスについても触れられ、多くの人が「あるある」と頷いていました。
また、データの追加が容易なことやキャッシュを意識しないで良いことなどは、今後の機能追加にも柔軟に対応できるという点でメリットであることが述べられていました。逆にデメリットは、上述したupdate時のオペレーションミスや、( スキーマフリー故の)スキーマデザインの難しさを挙げられていました。
全体の感想
ゲーム内のユーザーデータをMongoDBのupdateコマンドをうまく利用して効率良く処理しているところなどを見ると、さすがCyberAgentさんだなぁと感心しました。MongoDBのメリット・デメリットをきちんと見極め、実際の開発に次々とMongoDBを投入していく思い切りの良さは現在のCAさんの勢いを反映しているように感じます。
また、スキーマデザインの部分はとても重要であり、かつ難しい部分でもあります。皆さん、おなじところで頭を抱えられているんだなぁと感じました。
懇親会
懇親会もたくさんの方に参加していただき、大いに盛り上がりました。
サプライズで皆さんから筆者の26歳の誕生日を祝っていただきました。本当に驚き、喜びましした! ありがとうございました。本コミュニティと共に今後も大きく成長を続けていきたいと思います。
全体の総括とこれからの #mongotokyo の活動について
今回は前回よりも20名ほど多い、100名以上の方に参加エントリーしていただき、日々MongoDBの注目度が高まっていることに喜びを感じています。どの発表でも質問は絶えることがなく、とても有意義な勉強会になったことを大変嬉しく思います。また、会場の環境が素晴らしく、広さや綺麗さだけでなく、飲み物も無料で提供していただきました。そのような環境でリラックスして参加してもらえたのも良かったと思います。今後も同じ会場でMongoDB勉強会を継続していくつもりですので、是非とも一度足をお運びください。
勉強会の後、参加されたたくさんの方々にブログが書れました。筆者が調べた限りのブログをここに掲載させていただきます(漏れなどがありましたら申し訳ございません) 。皆さん、詳細なレポートありがとうございます。
さて、前回のレポート ではこれまでの#mongotokyoの活動について紹介しましたので、今回はここで今後の活動について触れておきます。
MongoDB勉強会はフューチャーアーキテクトさんの会場(大崎)をお借りして100名規模で毎月開催しています。MongoDBの機能や仕組みについての話からアプリケーションの応用まで、これからも幅広い内容で初心者から上級者までそこに意義を見いだせていただけるような会にしていきますので、皆さんお気軽に足をお運びください。また、分科会として以下の勉強会も発足しつつあります。
今後とも#mongotokyoをよろしくお願いします。