


生成AIでも人気のある機能のひとつが
Seed-VCについて
AIを利用した音声関係では、特に活発に開発が進んでいるのが
第877回の
今回紹介する
ボイスチェンジャーのツールはすでに多数存在しますが、Seed-VCは次の特徴を持っています。
- 事前の学習をせずとも音声変換できること
- GPUを使えばリアルタイムに近い速度で変換できること
- 音声データから直接変換できること
- ローカルで動かせること
- CLIのツールが充実していること
- オープンソースライセンスで提供されていること
いずれもほかの音声合成ソフトウェアでも備えている特徴ではありますが、すべてを備えたものとなると、それなりに限定されます。しかも変換品質も高いため、昨年に登場した当初も話題になりました。登場してからそこそこ時間が経ってしまってはいますが、今でも十分に使えるツールですので、Ubuntuで使う方法を改めて紹介しましょう。
ちなみにデモページが用意されています。まずは使ってみたいのであれば、インストールの前に触れてみると良いでしょう。
Seed-VCのインストール
Seed-VCはPythonソフトウェアですので、その流儀に従ってインストールすることになります。また、CPUだけで動かすには遅いためNVIDIA製のGPUも必要です。VRAMサイズについては明記されていませんが、少なくとも8GiB程度のVRAMがあれば問題なく動作しました。
NVIDIAのドライバーがインストール済みであるという前提で、追加で以下のソフトウェアをインストールしておきましょう。
$ sudo apt install nvidia-cuda-toolkit ffmpeg build-essential python3-dev git
nvidia-cuda-toolkitはSeed-VCがCUDAを使うために必要です。ffmpegは音声変換のためにインストールしていますが、Web UIを使いたいだけなら不要な可能性があります。build-essentialとpython3-devは、一部のPythonパッケージをインストールする際に必要です。gitは後ほど使用します。
Seed-VCは
uvコマンドのインストール自体は簡単で、次のコマンドを実行するだけです。
$ curl -LsSf https://astral.sh/uv/install.sh | sh downloading uv 0.9.7 x86_64-unknown-linux-gnu no checksums to verify installing to /home/ubuntu/.local/bin uv uvx everything's installed! $ file ~/.local/bin/uv /home/ubuntu/.local/bin/uv: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32, BuildID[sha1]=ed2da6f0b5b8218a687ae0de0527beda96a9b077, stripped
上記により~/.local/」~/.local/」uv」
実はUbuntuでログイン時に評価される~/.profile」
# set PATH so it includes user's private bin if it exists
if [ -d "$HOME/.local/bin" ] ; then
PATH="$HOME/.local/bin:$PATH"
fi
ログイン時に~/.local/」. ~/.profile」
次にSeed-VCのソースコードを取得して、Python 3.
$ git clone https://github.com/Plachtaa/seed-vc.git $ cd seed-vc $ uv python install 3.10 Installed Python 3.10.19 in 808ms + cpython-3.10.19-linux-x86_64-gnu (python3.10) $ uv python pin 3.10 Pinned `.python-version` to `3.10` $ uv venv Using CPython 3.10.19 Creating virtual environment at: .venv Activate with: source .venv/bin/activate
「uv python install」uv pyton pin」uv python list」~/.local/」
「uv venv」venvは<venv dir>bin/」uv venvで構築しておけば、あとはuvコマンド経由で何かを利用する限り、自動的にこのactivateを肩代わりしてくれるので便利です。
さて、Seed-VCに必要なPythonパッケージを追加することにしましょう。本家の手順ではpip -r install requirements.」
実際に実行してみましょう。
$ uv pip install -r requirements.txt error: Expected `--hash`, found `"--pre"` at requirements.txt:1:7 $ head -1 requirements.txt torch --pre --index-url https://download.pytorch.org/whl/nightly/cu126
どうやら一行目でエラーになってしまうようです。本来pipの--preや--index-urlをこのように書くことはできません。できないはずなのですが、通常のpipはこれをエラーとすることなく処理してしまいます。それに対してuvはより厳密にチェックしているため、上記記述だとエラーになってしまうようです。
対応方法としていくつかの手順が存在するものの、今回は
$ uv pip install --prerelease allow --index-url https://download.pytorch.org/whl/nightly/cu126 torch torchvision torchaudio $ uv pip show torch | grep Version Version: 2.10.0.dev20251102+cu126 $ sed -i 's/^torch/#torch/' requirements.txt $ uv pip install -r requirements.txt
1行目でPyTorch関連パッケージを個別にインストールしています。uv pip show torch」
それ以外のパッケージはrequirements.torch」uv pip install」
これで準備完了です。
Seed-VCのWeb UIを動かしてみる
さて、Web UIを起動してみましょう。Seed-VCには用途に応じて複数のWeb UIスクリプトが用意されています。
app_:V1ベースで音声を変換するWeb UIvc. py app_:V1ベースでの歌声に特化して音声を変換するWeb UIsvc. py app_:V2ベースで音声を変換するWeb UIvc_ v2. py app.:上記をすべて試せるWeb UIpy
README.によるとV1はよりリアルタイム性にすぐれており、V2はより元の話者の特徴を抑えるのに適しているようです。
今回は事前学習せずに使えれば良いため、app.を使うことにします。ちなみにapp.のみは事前学習データなどをコマンドラインオプションから渡せません。
uvコマンドでは、次の方法でapp.を起動できます。
$ uv run app.py --enable-v2 --enable-v1 Loading V2 models... (中略) Loading weights from nvidia/bigvgan_v2_22khz_80band_256x Creating V1 interface... * Running on local URL: http://127.0.0.1:7860
最初の実行時はHugginge Faceから数GiB程度のモデルデータをダウンロードしますので注意してください。VRAMは起動しただけで2.
画面にも表示されているように、http://」
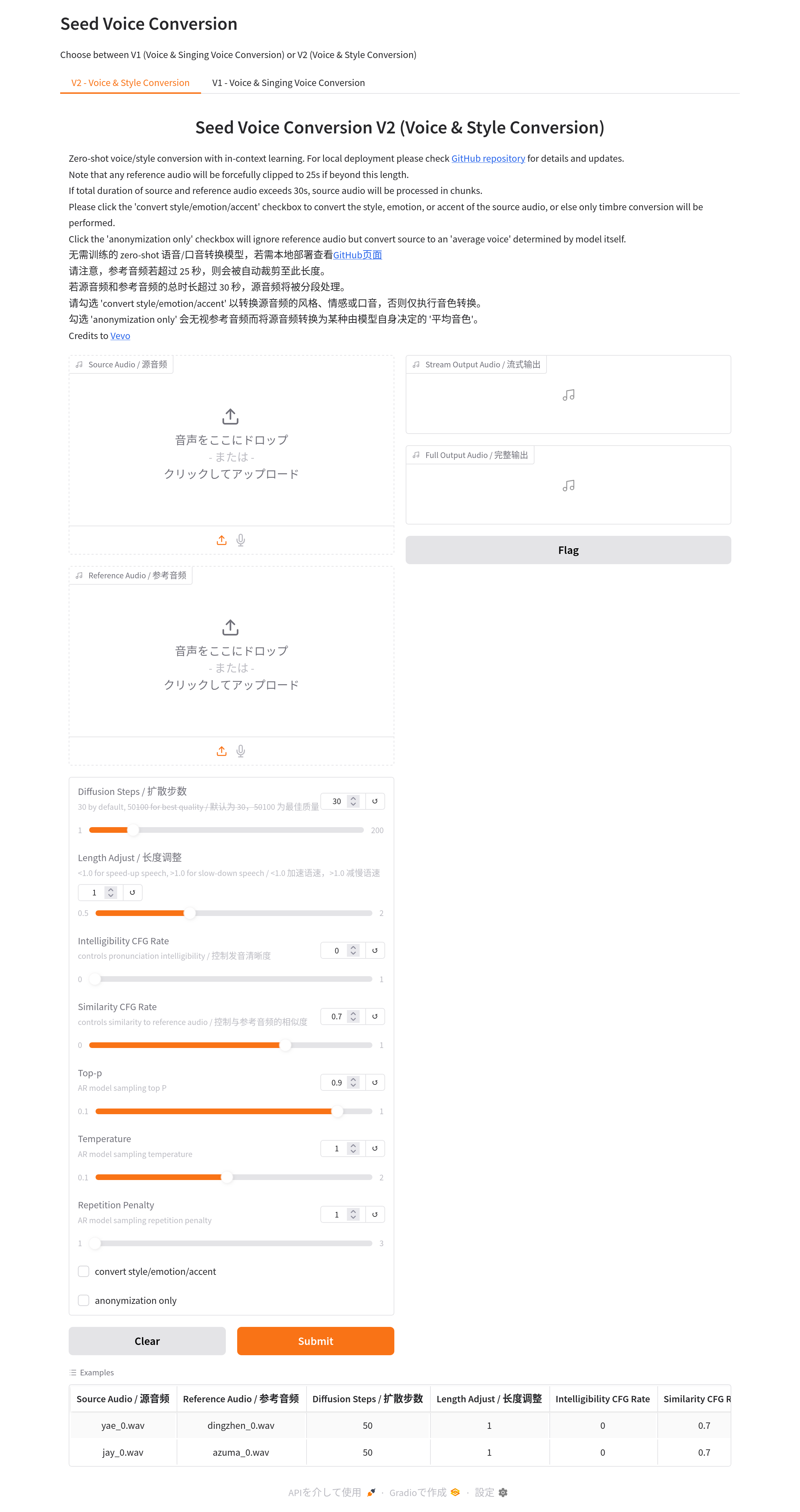
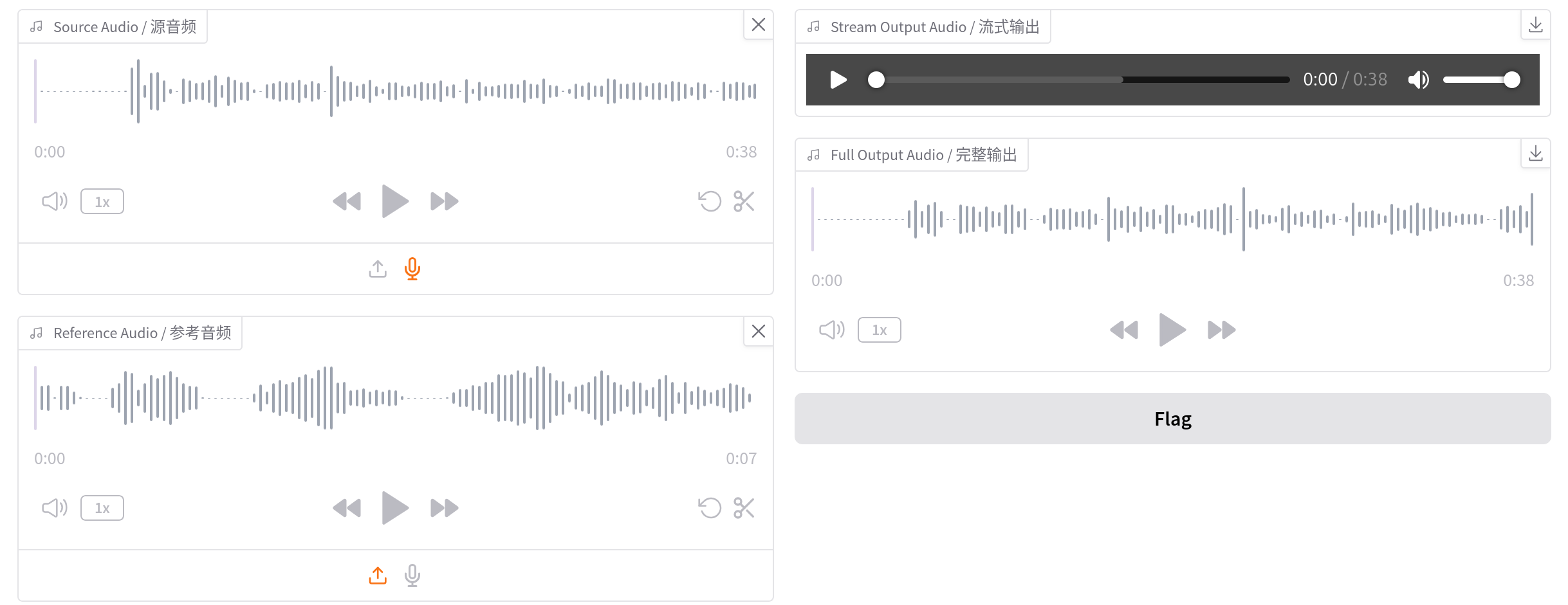
「Source Audio」
設定パラメーターはいくつかありますが、最初のうちは初期値で問題ないでしょう。参考までにV2のパラメーターは次のとおりです。
- Diffusion Steps:ステップ数を増やすほど品質は向上するが遅くなる。30から50くらいが推奨
- Length Adjust:音声の速度を調整する、小さいとゆっくりになり、大きいと早口になる
- Intelligibility CFG Rate:発音の明瞭さを調整する
- Similarity CFG Rate:話し方を参照音声にどこまで近づけるか調整する
- Top-p:出力時の多様性を調整する
- Temperature:出力のランダムさを調整する
- Repetition Penalty:音の繰り返しを抑制する
- convert style/
emotion/ accent:アクセントや感情の変化も適用する - anonymization only:参照音声を無視して、平均的な声に変換する
「Diffusion Steps」
準備ができたら
GPUを使う場合は、おおよそリアルタイムで変換してくれます。つまり1分間の音声データを変換するなら1分間ぐらい必要です。
出力先は2種類あります。
- Stream Output Audio:最初の30秒を変換したら表示される
- Full Output Audio:すべての音声を変換したら表示される
Streamのほうは30秒ぐらい変換した時点で再生ボタンが表示されます。その状態で再生すると、変換が進むごとに音声チャンクが末尾へと追加されるので、変換の完了を待つことなく確認が可能です。どちらも変換が完了したら、右上のボタンから変換後の音声ファイルをダウンロードできます。
たとえば今回だと次のようなマシンを使って変換してみました。
| Machine | MINISFORUM MS-A2 |
| CPU | AMD Ryzen 9 9955HX 16C/ |
| Memory | DDR5-5600 128GiB |
| GPU | RTX A1000 8GiB |
| OS | Ubuntu 25. |
参照音声として、
このコーパスファイルにはzipでアーカイブされた多数のwavファイルが保存されています。そこで、1ファイルのみを取り出し
$ unzip -p tyc-corpus1.zip \ 'つくよみちゃんコーパス Vol.1 声優統計コーパス(JVSコーパス準拠)/01 WAV(収録時の音量のまま)/VOICEACTRESS100_001.wav' > tsukuyomi01.wav
この状態で変換した結果が次のとおりです。
最初の2ファイルは、元データの訛り、つっかえ、読み間違いをそのまま維持しつつ変換されていることがわかるでしょう。3番目はあまりうまく変換できませんでした。元データからして抑揚のない喋り方だったのでそのあたりも影響している可能性があります。最後はどっかで聞いたことのあるおっさんの声になっています。雑音が多いのはマイクの問題です。
リアルタイム変換ツールを使ってみる
Web UIでは
Seed VCにはそれ用のGUIアプリケーションの実装も用意されています。ただしこれを使うためにはサウンドデバイスをコントロールするライブラリが必要です。Ubuntuの場合は次のパッケージをあらかじめインストールしてください。
$ sudo apt install libportaudio2
GUIアプリケーションを起動するには、次のように実行します。
$ uv run real-time-gui.py

使い方はWeb UIと大差ありません。
あとは