



最近のRubyインタプリタの進化において非常に重要なトピックの一つが、JITコンパイラの登場です。特にShopifyのJITコンパイラチームを中心に開発されたYJITは、世の中で広く使われているRailsアプリケーションを有意に高速化できるJITコンパイラとして、既にproduction-readyであると評価されており、各所で採用が進んでいます。
RubyKaigi 2023 2日目のMaxime Chevalier-Boisvertさんによるキーノートでは、開発チームがYJITを開発するにあたってどういったアプローチで開発を進めてきたのか、その中核であるData-driven approachとは何なのかということを中心に話が展開されました。このレポートではその内容について細かく振り返っていきたいと思います。

そもそもJITコンパイラとは
キーノートの内容に入る前に、JITコンパイラについて簡単におさらいをしておきましょう。JIT(Just-In-Time)コンパイラとは、その名のとおり実行時に必要なものを必要なタイミングでコンパイルすることで、プログラムを高速化するための仕組みです。とはいってもRubyの中でいうコンパイルにはいくつか段階があるので、そこから復習していきましょう。
現在のRubyはプログラムを実行する時に、まずRubyVM(YARV)の命令列にプログラムコードをコンパイルします。この命令列をInstruction Sequence(ISeq)と呼びます。
例えば以下のようなRubyコードをISeqにコンパイルすると次のようになります。ruby --dump=insns <rbfile>で出力できます。
def hello
puts "hello world"
end
hello
== disasm: #<ISeq:<main>@ruby_iseq.rb:1 (1,0)-(5,5)> (catch: false) 0000 definemethod :hello, hello ( 1)[Li] 0003 putself ( 5)[Li] 0004 opt_send_without_block <calldata!mid:hello, argc:0, FCALL|VCALL|ARGS_SIMPLE> 0006 leave == disasm: #<ISeq:hello@ruby_iseq.rb:1 (1,0)-(3,3)> (catch: false) 0000 putself ( 2)[LiCa] 0001 putstring "hello world" 0003 opt_send_without_block <calldata!mid:puts, argc:1, FCALL|ARGS_SIMPLE> 0005 leave
このようにして、コンパイルされたISeqはRubyVMの中でC言語で実装された各処理と対応し、この命令をRubyVMが実行することでRubyはプログラムを実行します。
基本的にRubyのプログラムは連続したメソッド呼び出しの連鎖です。Rubyはオブジェクトの型が何であるかを調べその情報を元にメソッドのルックアップを行なって、RubyVMの中で決められた手続きに則ってメソッドを実行します。もしこの時に、これらの型検査やメソッド探索の処理をバイパスして直接機械語を実行し、同じ結果を得ることができれば高速化できそうではないでしょうか。
現実のコードでは、あるメソッドで利用される変数の型はかなり狭い範囲に特定できるケースが多々あります。そういったコードが多く実行されるなら、実行中にVM命令をある程度決め打ちで機械語にコンパイルして変換のオーバーヘッドがかかったとしても、総合的な実行時間ではより高速に実行できる可能性があります。
これを行うのがJITコンパイラです。JITコンパイラはこのように機械語のネイティブコードにコンパイルすることで高速化を図るものなので、CPUアーキテクチャそれぞれのネイティブコードに対応して実装する必要があります。世の中のあらゆるCPUアーキテクチャに対応するのはコストがかかり過ぎるため、RubyのYJITでは現在x86_
もちろん、こういった処理には一定のコストがかかります。機械語にコンパイルし結果をキャッシュしておく際に余計なメモリが必要になりますし、コンパイル対象が適切でなければコンパイルにかけたコストを回収できません。もしJITコンパイル時に立てた前提が後から間違っていたと判明したら脱最適化と呼ばれる処理を経て通常のRubyVM実行に戻す必要もあります。このように理屈自体は単純なのですが、実際にJITコンパイラでプログラムを速くするためには様々な工夫が必要になるのです。
さて、JITコンパイラがどういったものかについて非常に簡単ではありますが振り返ってみたところで、ここからは今回のキーノートの内容とともに、どうやってYJITが実現されたのかについて見ていきましょう。
冒頭でも触れましたが、今回のトークでキーワードとなるのはData-drive approachです。
YJITはどこから来たのか
YJITは2年以上前にCRubyに新しいJITコンパイラを実装するというプロジェクトとして始まりました。YJITのそもそものゴールは、以下の内容を実現することです。

- 既存のRubyコードと100%の互換性を保ち、どんなRubyコードでも動く
- 現実のRubyアプリケーション
(特にRailsを利用したWebワークロード) を10%以上高速化する - 既存のコードより遅くならない、最悪のケースでもただ高速化しないだけ
- 十分にテストされており安定している
- (できるならupstreamのCRubyに取り込まれる)
キーノートスピーカーのMaxime氏は、the University of Montrealでコンパイラデザインの研究をしていました。MATLABのJITコンパイラの最適化の研究を経て、JavaScriptの最適化の研究をしていましたが、Mozillaの開発者がSpiderMonkeyにJITコンパイラを実装する研究を先に公開したため、別のアプローチを調査することになりました。そこで型解析なしで型をより上手く特定する方法に注目しました。こういった経験がYJITの実装に活きています。
YJITの基本的な考え方
YJITの中心になっているのはLazy Basic Block Versioning(LBBV)という手法です。詳細は論文を参照していただきたいのですが、ここでは私のLBBVについての理解を簡単に解説します。
- LBBVの仕組み
-
コードにおけるBasic Blockとは、分岐を持たず一つのentryポイントと一つのexitポイントだけを持つ、コードシーケンスを指します。プログラムはその言語の制御構文として分岐が見えていなくても実際に実行される処理の中には様々な分岐が含まれます。例えばRubyのような動的型付け言語では、
x.という単純なコードの中にも、to_ i xの型によって処理の分岐が発生します。この型のコンテキスト毎にBasic Blockを複数バージョン生成して保持すれば、そのブロックの中では特定の型であることを前提したコードを生成し型検査を削除できます。また、この型コンテキストは後続のBasic Blockにも引き継ぐことができます。この時、有り得るすべてのバージョンのBasic Blockをeagerlyに
(前もって事前に) 生成しようとすると、組み合わせ爆発が起きてとんでもない量のバージョンが生成される危険があります。しかし、現実のコードでは有り得る型の組み合わせの中で、極一部しか使われないことがほとんどです。そこで、実行時に必要になったタイミングで新しいBasic Blockのバージョンを生成するように、生成タイミングを遅延させlazilyに処理することで生成されるブロックのバージョン数を大きく削減できます。 型推論などのコストがかかる処理を捨てて、こういった割り切りの元でBasic Blockを複数バージョン保持することで、実行時に十分なほど型検査をスキップできる、というのがLBBVのアプローチです。
この考え方の元で、YJITは当初想定していたよりも大きな成果を上げることができました。それを可能にしたのは、徹底したData-drivenなアプローチです。
ベンチマークの選択
Maxime氏は最初にベンチマークの選択について話しました。
Rubyにはoptcarrotというマイクロベンチマークプログラムがありましたが、これはCRubyの改善のためには有用なものでしたがYJIT開発チームが求めていたものではありませんでした。ほとんどのRubyユーザーはNESエミュレーターのためにRubyを使っておらず、optcarrotは現実のRubyコードを代表してはいません。
JITコンパイラは非常に複雑で最適化のためにとても大量の選択肢があります。その中で正しい方法を選ぶためには、自分達がどういったワークロードの高速化に取り組んでいるのかにフォーカスする必要があります。自分達の目的を誤魔化さずに適切なベンチマークを選択することを強調していました。

そこでYJIT開発チームは、YJITの開発に特化したベンチマークスイートを開発しました。それがYJIT-Benchです。YJIT-Benchには以下のような要件がありました。
- すべてのYJIT開発者が簡単にセットアップできて実行可能であること
- シンプルで頻繁に実行してもストレスがないこと
- ワンコマンドで実行できて、10分~30分で結果が得られる
- よく整理され要約されたベンチマークセットであること
YJIT-Benchは3つのカテゴリに分かれています。実際に広く利用されているrubygemsをベースとしたWebのワークロードにフォーカスしたヘッドラインベンチマーク、optcarrotなどを利用した小さいが総合的なベンチマーク、そして特定のケースに特化しパフォーマンスリグレッションなどを検知するためのマイクロベンチマークの3つです。
目的ごとにベンチマークを準備することで、リグレッション対策や段階的な最適化といったアクションを取れるようにしながらも、大きなゴールを見失わないようにする工夫が重要な点でしょう。
正しくベンチマークを選択した後は、その実行方法についても考慮しなければいけません。より良い計測結果を得るためには、ベンチマークの実行状況が安定している必要があります。例えば、CPU frequencyのスケーリングをオフにしてCPU温度によるスロットリングを回避したり、メモリアドレスのランダム化をオフにしたり、特定のシングルコアで実行することでCPUキャッシュの影響を最小化するなどの工夫ができます。
実行結果にブレが大きいと正しく評価できなくなります。YJIT開発では、実行環境にまできっちり気を配ることで、ベンチマーク結果がノイズにならないようにしっかり統制を取っています。一つ一つは簡単なことですが意識から抜けがちなことで、やるべきことをきっちりこなすのがいかに大事なことかがよく分かります。

余談ですが、キーノートではおそらく
さて、ベンチマークはどれぐらいのパフォーマンスであるかの概要をつかめますが、いくつかの最適化は一つ一つの影響が小さくてベンチマークだけで計測するのは難しいものです。そのため、ベンチマークスイートとは異なったメトリックがいくつか必要になります。例えば、実行された命令の数や生成された機械語コードのサイズやインタプリタへのexitの発生回数などです。これらのメトリックの取得のために--yjit-statsというオプションが実装されています。
--yjit-statsオプションを利用すると、メソッド呼び出しがインタプリタにexitした要因の統計や、YJITで生成されたコードが全体の命令実行に占める割合などが表示されます。これらの指標はJIT-edなコードの実行時間を最大化するために利用されています。
実際にデプロイしてベンチマークを取得する
Shopifyでは現実のアプリケーションがどの程度高速化されるのかを知るために、実際にデプロイしてみてproduction環境上でもベンチマークを取得しています。この時重要なことは、実験環境を適切にコントロールすることです。
production環境でベンチマークを取るにあたって、一番単純な方法は変更を加えたコミットをデプロイしてみて、変更前のコミットのメトリックと比較しどうだったかを確認する方法が考えられますが、これは余り良い方法ではありません。実際のアプリケーションでは時間や場所が異なればワークロードも異なってくるからです。時間や提供範囲が異なっていては正しい結果が得られません。そのため実験環境を適切に構成することが重要になります。

YJITの検証では、実験環境を3つのグループに分けました。test group(with YJIT), control group(without YJIT), stats groupの3つです。そしてすべて同一のRuby commitを利用し、すべてのクラスタ、すべてのロケーションにデプロイします。statsの取得を分離しているのは、statsを取得すること自体がパフォーマンスに影響を与える可能性があるからです。
このように実験環境を構成することで、全世界で同時にwith YJITな環境とwithout YJITな環境のパフォーマンスを比較できます。
データを取得する上で、比較したい箇所以外は可能な限り同一の状況を構成し、検証グループとコントロールグループを分けるのは基本の行いです。しかし、こういった環境を構成するのは地味に面倒なもので、往々にして手を抜きがちな箇所でもあります。ベンチマークの選択においてもそうでしたが、YJIT開発におけるData-drive approachとは、こういったデータ収集の基本を決して疎かにしないところが最も重要な点であると言えるでしょう。
また、直近の計測ではYJITによって平均で18%の高速化の結果が得られていることも紹介していました。18%も高速化すれば、とても多くのサーバー費用の削減につながります。素晴らしい成果です。
JITコンパイラのトレードオフと更なる改善
ソフトウェア開発においては何事においてもトレードオフがあります。JITコンパイラにはどうしてもコンパイルにかかる時間やメモリ消費量などの点でコストがかかります。コストとメリットのバランスを取るためにいくつかの工夫が必要です。
例えばシステムの初期化時点でのみ必要な処理をJITコンパイルしても、そのコードが二度と実行されないなら完全にコンパイル時間の無駄になります。単純な手段としてメソッド呼び出しの回数に閾値を定めてその回数を越えたらJITコンパイルの対象にする、といった仕組みを導入できます。YJITでは--yjit-call-thresholdというオプションで制御可能になっています。シンプルですが現実的には十分に効果があります。
メモリ消費量については、ruby-3.
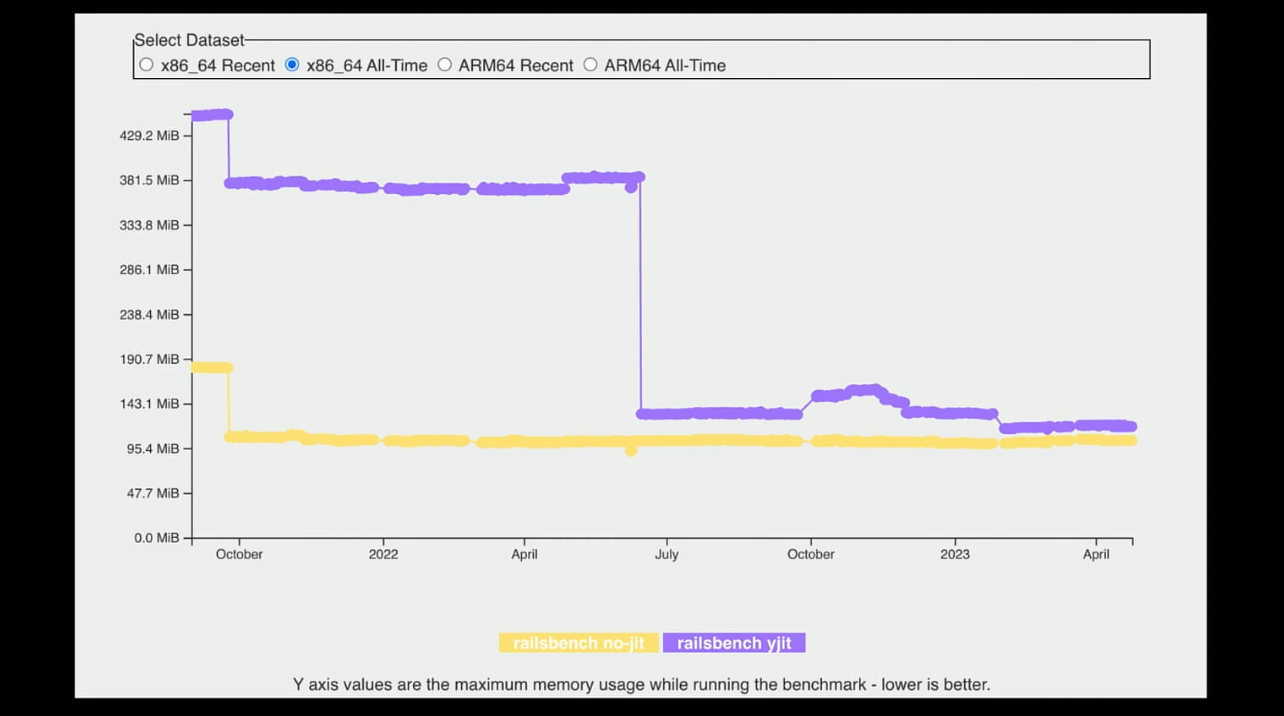
また、ruby-3.--yjit-pauseオプションを付与して実行することでYJITはpause modeで起動します。これによりシステム起動時のJITコンパイルの意義が薄い処理を実行している際にはYJITを完全に停止しておいて、起動処理が完了した後にYJITを起動できるようになります。無駄なコンパイル時間やメモリ消費の削減に効果がありそうですね。
その他にも、Register Allocation
まとめ
今回のRubyKaigi 2023のYJITに関するキーノートトークは、昨年のRubyKaigi 2022のYJITに関するキーノートより身近に感じるテーマだったように感じました。
昨年はアセンブラとCPUレイヤの話が多く、私自身としてもそこまで低レイヤのことを考えた経験はほとんどなかったため、話についていけているのかよく分からないところがありました。一方で、今年はYJITという問題に立ち向かうために、物事を適切に扱うにはどうすればいいかというのが主なテーマだったように感じます。
YJITという非常に高度な仕組みを開発しているチームであっても、一つ一つのやり方は難しいことではありません。正しく計測し、正しくフィードバックを得て、試行錯誤する、この繰り返しです。しかし、これを
このレポートが、皆さんのRubyKaigi 2023の振り返りの一助となれば幸いです。
参考文献:
- Maxime Chevalier-Boisvert and Marc Feeley, Simple and Effective Type Check Removal through Lazy Basic Block Versioning (ECOOP 2015)
- M. Chevalier-Boisvert, N. Gibbs, J. Boussier, S. X. Wu, A. Patterson, K. Newton, and J. Hawthorn, YJIT: A Basic Block Versioning JIT Compiler for CRuby (VMIL 2021)