2024年2月15日、OpenAIは動画生成AIモデル「Sora 」を発表しました。わずか数秒の動画を生成するために試行錯誤が続く中、テキストから約1分の動画が生成できるAIモデルの発表は、多方面で大きな反響を呼びました。
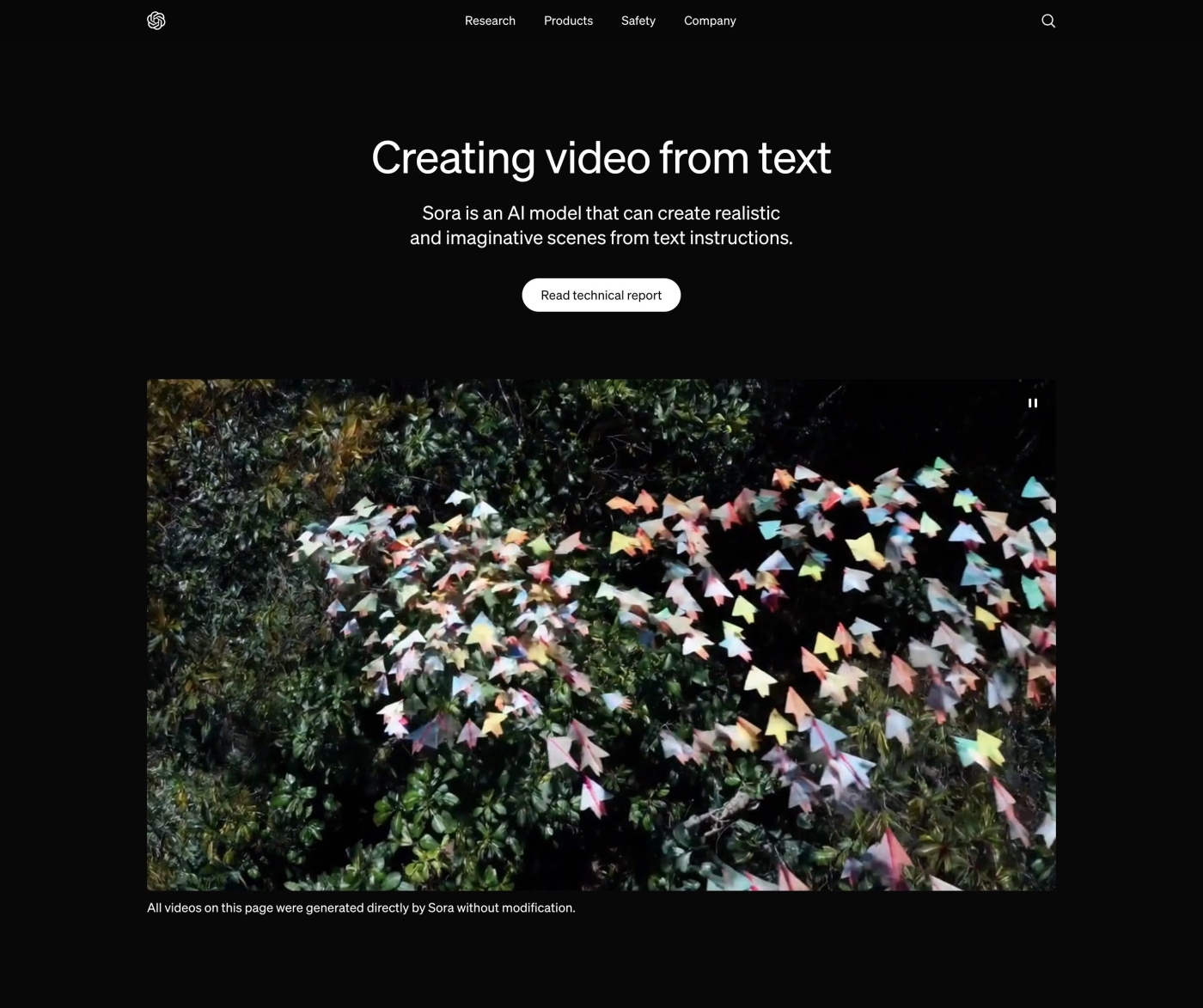
図1 OpenAIが発表した、動画生成AIモデル「Sora」のウェブサイト。ユーザーがテキストで要求したものが何か、それらがどのように存在するのかも理解して、動画を生成するAIモデル 5月14日には、Google DeepMindからも、動画生成AI「Veo 」が発表されました。こちらも「Sora」同様に、1分以上の動画が生成できるAIモデルとして注目を集めています。
図2 Google DeepMindが発表した、動画生成AI「Veo」のウェブサイト。自然言語を理解して、テキストプロンプトに正確な動画を生成するのが特徴のAIモデル 今年に入り、テキストから長時間の動画が生成できるAIモデルが登場してきました。しかし、こうした動画生成AIが登場するまでには、どうしても超えなければならない、解決が必要な技術的課題が存在していました。
画像生成AIの登場から、大きな驚きを与えた動画生成AIへと続く、生成AIの関連技術の進展をたどりながら、今後の生成AIが生み出す、新たな流れを探っていきます。
プロンプトから動画を生成する、各モデルの特徴
OpenAI「Sora」の特徴
OpenAIの「Sora」は、テキストで指示すると、最長1分間の動画を自動生成するAIモデルです。OpenAIの「Sora」のウェブサイトで公開されている動画は、すべて「Sora」によって生成されています。
「Sora」で生成された「東京の街を歩く女性」の1分間の動画。プロンプトで指定した「黒のレザージャケット」「赤いロングドレス」「サングラス」といった外見や、「自信に満ち、さりげなく歩いている」といった人物の態度への指定をしっかり表現している
「Sora」によって生成された動画は、非常になめらかな印象です。従来の動画生成AIモデルでは、登場する物体や明るさが各フレームごとに異なるため、画面のどこかが常に点滅しているような動画になっていました。「 Sora」が生成した動画には、そうした“ 見づらさ” がないのも驚きです。
現時点では、物理的な相互作用を正確にシミュレートできない点(女性の足の運びがおかしくなる) 、時間の経過に合わせて発生する出来事を正確に描写できない(女性の右手にあった黒いバッグが消える)などの問題点もあります。
それ以上に、プロンプトから簡単にリアルな映像を生成できる「Sora」には、有害コンテンツの生成や誤った情報の拡散、学習データによるバイアスなどの危険性も存在します。問題に対処するため、OpenAIでは「Sora」の一般公開を行わず、「 Red Team」と呼ばれる、一部の専門家による検証作業を継続中です。また、AIモデルの改良方法に関するフィードバックを得るため、一部のクリエイターに「Sora」を提供しています。
Google DeepMind「Veo」の特徴
「Veo」は、テキストプロンプトから、1分を超える1080p(画面アスペクト比が16:9、解像度が1920x1080ピクセルの解像度)の動画が生成できるAIモデルです。あらゆる種類の映画効果も理解しているため、プロンプトの追加で、効果を加えた動画の生成・編集も可能です。
動画1 DeepMind「Veo」によって生成された、ディストピアを走行する車の動画。1分の動画は「Veo」から直接生成されたもので、一切の編集は行われていないVIDEO
将来的には、機能の一部を自社のサービスである「YouTube Shorts」などに導入予定で、数週間以内に米国内の利用者向けに「labs.google」のツール「VideoFX 」として提供が開始されます。
生成された偽の動画による悪影響を防ぐため、生成された動画すべてに「生成AIで制作されたことを示すラベル」を組み込んで、安全性を高めているのも「Veo」の特徴です。
動画生成AIに至るまでの技術的遷移
テキストプロンプトから長時間の動画が生成できる「Sora」ですが、このような動画生成AIモデルの登場を予想していた方は、少なくなかったでしょう。生成AIに関する技術の問題点と、それを解消するべく登場してきた技術が、画像生成AIをどのように発展させてきたのかを振り返ると、その理由が明らかになるでしょう。
画像生成AIモデル登場時の問題点
2022年8月、誰もが無料で利用できる画像生成AI「Stable Diffusion」が公開されました。登場直後から、画像生成AIではテキストプロンプトで生成される画像の予測が不可能なことや、キャラクターや構図、ポーズなどを確実に再現させる法則性がないことなどが指摘されていました。
筆者も、登場したばかりの画像生成AIモデル「Stable Diffusion」を利用した画像生成に挑戦 しました。その際、テキストプロンプトを使った画像生成で問題となっていた点は以下の通りです。
同じ人物を固定したまま、別の画像を生成するのが難しい
ポーズや構図の指定を行っても、反映されない場合が多い
たった1枚の画像を生成するのにも、時間がかかる
当時は、こうした問題点を解消するため、seed(種)と呼ばれる画像生成の初期データを固定しながら、同じプロンプトで何度も画像を生成しました。さらに、制作した大量の画像の中から、自分が求める画像を選別するという、気の遠くなるような作業が必要でした。
プロンプトからの離脱と、技術による表現の拡大
画像生成AIを使った画像生成では、テキストでの指定が必要です。ただし、このテキストプロンプトの重要度は、ここ1年間で大きく低下しました。
最大の変化は、キャラクターやポーズなどをテキストで指定せず、ユーザーが求める表現に特化した技術を組み合わせて使用することで、生成画像にユーザーの意図を確実に反映させられるようになったためです。
ここでは、画像生成AIモデルでの画像生成を大きく変えた技術である「LoRA(Low-Rank Adaption)」 、「 ControlNet」 、「 LCM(Latente Consistency Models) 」について、解説します。
LoRA(Low-Rank Adaption)による、人物やキャラクターの指定
「LoRA(Low-Rank Adaptation) 」は、すでに学習されているAIモデルに加えて、人物や場所などの指定を可能にする技術です。
人物の表情や背景、表現に欠かせない小物など、プロンプトよりも確実で細かな指定が行えることから、「 LoRA」を組み合わせて画像生成することで、求める表現を的確に生成できるようになってきました。
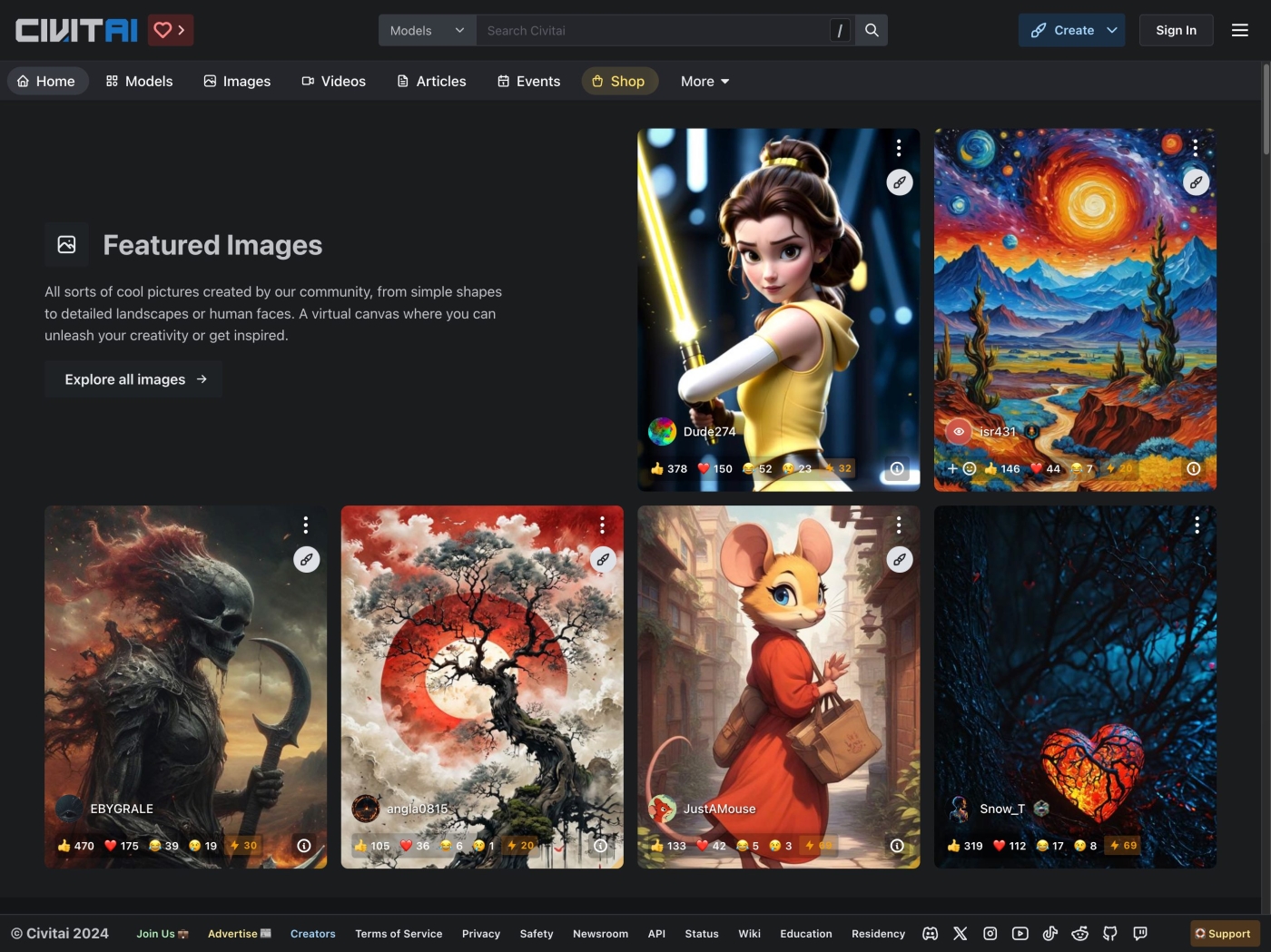
図3 利用可能な「LoRA」の検索やダウンロードが可能なプラットフォームのひとつ、『 Civitai 』 。さまざまな生成AIモデルや「LoRA」がダウンロード可能だが、著作権的に問題のあるものも多い 「LoRA」はインターネットを通じて公開されているものの、商用利用などのライセンスがはっきりしないもの、芸能人などの実在する人物、著作権的に問題があるアニメ作品や映画の登場キャラクターの生成に特化したものなど、利用に法的な問題点を含むものも数多く存在しています。実際の利用には、十分な注意が必要です。
ControlNetによる、ポーズの指定
「ControlNet」は、人物のポーズや画像内のエッジ(輪郭線や境界線など) 、深度マップ(画像の各画素に対するカメラからの距離を色で示したもの)などの条件を指定することで、テキストプロンプトでは表現できない要素を指定できる技術です。
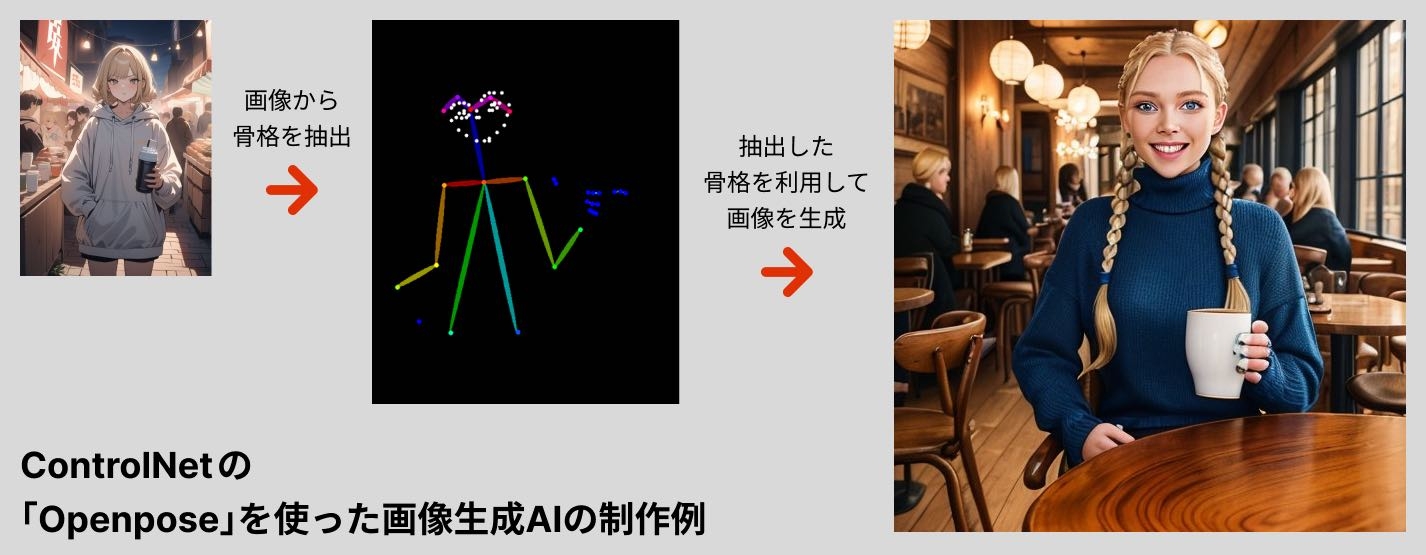
「ControlNet」には、プリプロセッサ(前処理)と呼ばれる多くの機能があります。そのひとつ、「 Openpose」では、人間の骨格を表現した棒人形を操作してポーズを指定することで、テキストプロンプトでは実現が難しかったポーズの再現が可能になりました。
図4 「 ControlNet」の「Openpose」の利用例。元画像(左端)から、人間の骨格を抽出(中央) 。その骨格を別のプロンプトと併用して、新たに画像を生成(右端) 。テキストプロンプトで指定しなくても、画像から抽出したポーズが再現されている それ以外にも「Canny(線画抽出) 」 「 Depth(深度情報抽出) 」 「 Inpaint(画像修正) 」 「 Tile(高解像化) 」 「 Scribble(線から画像生成) 」といった機能を使って、生成画像の詳細なコントロールが行えます。
LCM(Latente Consistency Models)による、高速な画像生成
LCM(Latent Consistency Model) は、2023年10月に中国の清華大学の研究チームが発表した、画像生成の高速化技術です。
これまでの画像生成AIモデルでは、画像生成の完了するまでに、少なくとも20程度のステップ(処理回数)が必要でした。LCMでは画像生成の完了までを数ステップで完了させるため、画像生成速度を5–10倍程度まで高速化できます。
LCMをLoRA化した「LCM-LoRA 」が公開されると、「 Stable Diffusion」と組み合わせて、画像生成の高速化が手軽に試せるようになりました。
画像生成の完了までのステップが減少して、大幅な時間の節約となるだけでなく、ほぼリアルタイムでの画像生成も可能となるため、この特性を生かしたアプリケーションへの導入も広がっています。
動画2 画像生成AI「Stable Diffusion」を組み込むプラグイン「krita-ai-diffusion 」を追加した、オープンソースのペイントソフト「Krita 」。「LCM-LoRA」によって、リアルタイムに近い高速な画像生成が可能になっているVIDEO
技術で解決されてきた、生成AIの問題点
生成AIに関連する技術の進展で解消された問題点は、「 一貫性の保持」と「生成の高速化」です。
「一貫性の保持」が可能になれば、制作現場で必要不可欠な、全体の世界観を表した統一感あるビジュアルやアイテム、映像の作成が可能になります。生成AIによる表現のばらつきが一定の枠内に収まることで、低い確率に頼った“ 運任せの作業” は減少し、作業の効率化と質の向上が実現できます。
「生成の高速化」が可能になれば、画像や動画を生成する際の時間を短縮できます。また、リアルタイムの反応に合わせて、生成AIを利用できるため、個人などが利用するアバターやバーチャルYouTuber(VTuber)などの動画生成にも応用が進んでいます。
「一貫性の保持」と「生成の高速化」が実現されたことで、最も恩恵を受けたのが、動画生成AIの分野です。以前から、画像生成AIを使ったフレーム(1枚1枚の静止画)生成から動画を作成する技術はあったものの、膨大な時間が必要なことや連続生成したフレーム内容の一貫性が保てないことが課題でした。
新たな技術によって、動画生成における大きな課題が解消されたことを考えれば、今回の「Sora」や「Veo」の登場は、当然の流れだったと言えるでしょう。
「一貫性」と「高速化」を実現した、生成AIの今後と向き合うべき課題
新たな技術で「一貫性」と「高速化」を実現してきた生成AIは、これからどのような広がりを見せるのでしょうか。最近話題となった技術や企業の動きから、今後の生成AIの流れを予測していきます。
また、生成AIの利用が広がる中で、利用を妨げる問題点も見えてきました。生成AIの安全性と信頼性を確保するため、これから企業や私たち自身が向き合うべき課題を考えます。
広がる生成AIの利用領域
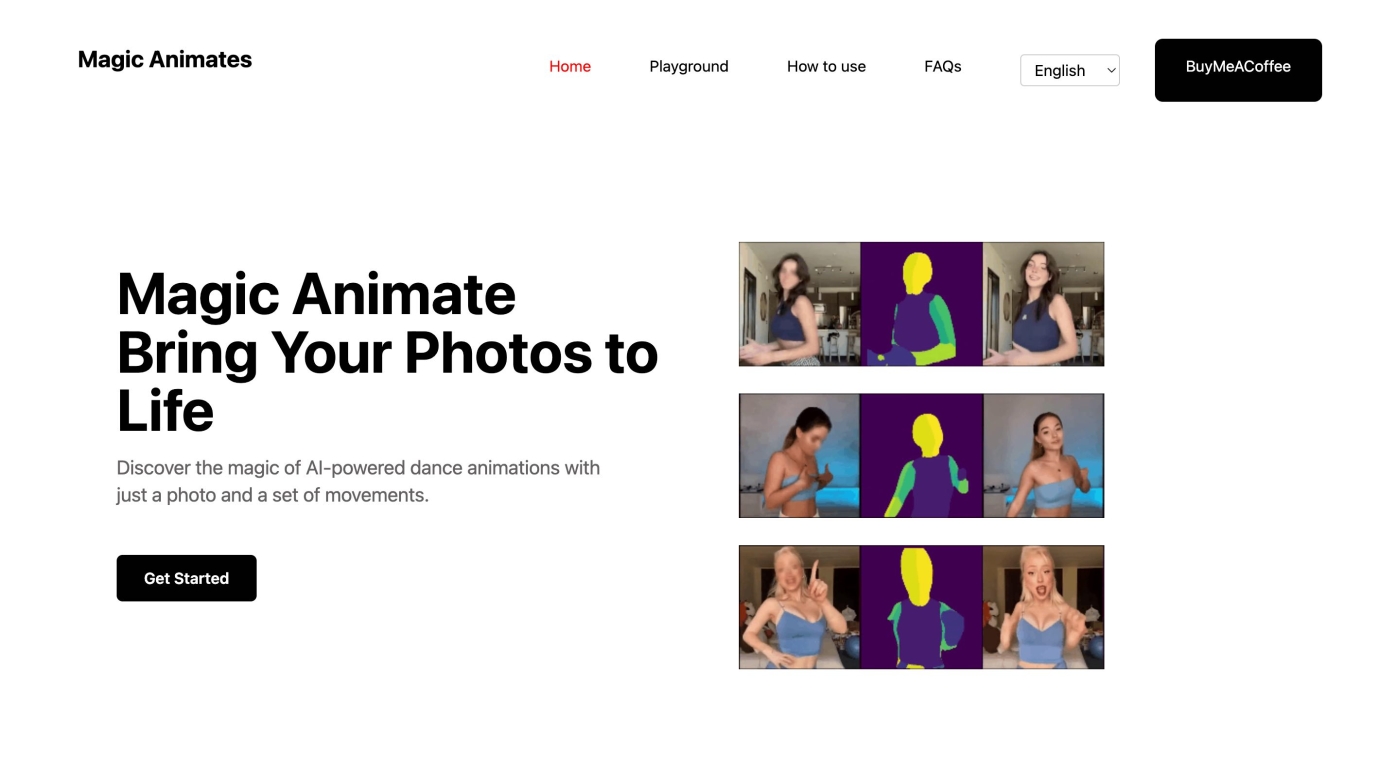
生成AIの技術は、より簡単に、確実な成果が出る方向へと向かっています。ByteDanceが開発した、AIアニメーションツール「Magic Animate 」のように、わずか1枚の画像をベースにして、その内容を動画にまで適用させてしまう、驚くべき技術も登場しています。
図5 ByteDanceが開発した、AIアニメーションツール「Magic Animate」 。たった1枚の静止画とモーションデータを組み合わせるだけで、人物やキャラクターの動画が生成できる。特定部分の一貫性が保持されており、他の動画生成AIモデルと比較して、画面のちらつきが非常に少ない また単純な進化ではありますが、高速化の影響は非常に大きいと感じています。生成AIの利用で、繰り返しや大量の作業への負担は大幅に軽減されます。人間の能力を補助しながら、より注力すべき仕事、より高品質な製品や作品づくりにも貢献していくはずです。
動画3 OpenAIが発表した対話型AI「ChatGPT」の最新版、「GPT-4o」でじゃんけんを行う様子。処理スピードが2倍に高速化した「GPT-4o」の音声認識は、反応速度が人間同士の会話時と同じレベルに向上。会話への割り込みにも素早く対応するだけでなく、同時に文字や画像、音声のすべてを認識しながら回答できるVIDEO
まだ規模は小さいものの、企業による生成AIを使った商業サービスの展開や、企業のキャンペーンやCMでの利用事例も増えています。生成AIを取り巻く環境が整備されれば、より大規模なビジネスへと発展する可能性も秘めているでしょう。
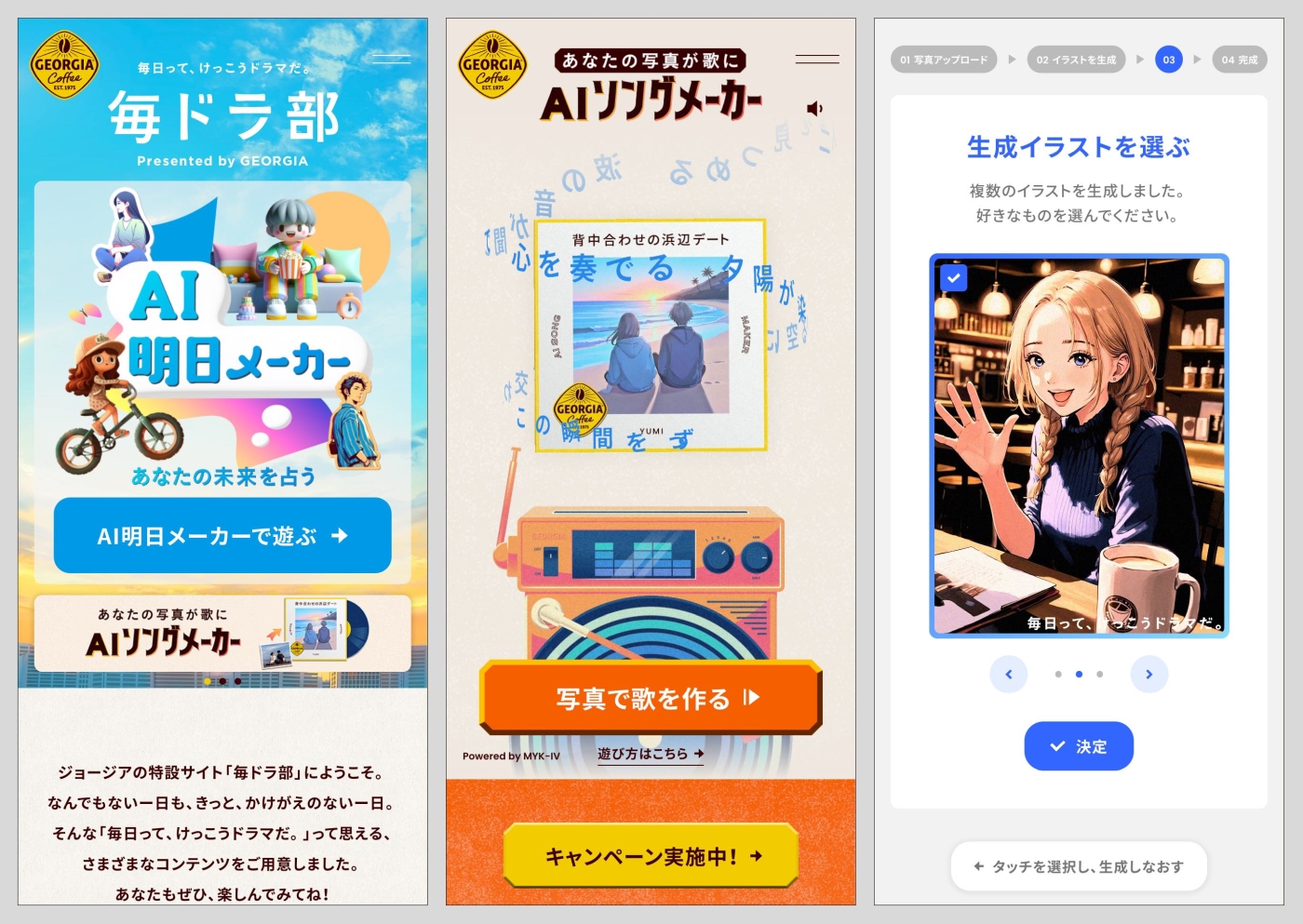
図6 日本コカ・コーラのコーヒーブランド、「 ジョージア」の体験型プラットフォーム「毎ドラ部」 。生成AIを使った占い「AI明日メーカー」や作曲できる「AIソングメーカー」 、イラスト作成ができる「AIイラストメーカー」などのコンテンツが用意されている
動画4 伊藤園の特定保健用食品「お~いお茶 カテキン緑茶」のテレビCM、「食事の脂肪をスルー」篇。AI技術で生成したタレント「ケイティー(Katea)」が製品の機能性を説明するという内容VIDEO
利用者を拡大する、AIモデルの小型化
生成AIのモデル自体は、小型化が進んでいます。現在は、データをクラウドで処理する大規模なAIモデルの運用が一般的ですが、スマートフォンのようなデバイスでも動作する、小型で効率的な生成系AIモデルも登場しています。
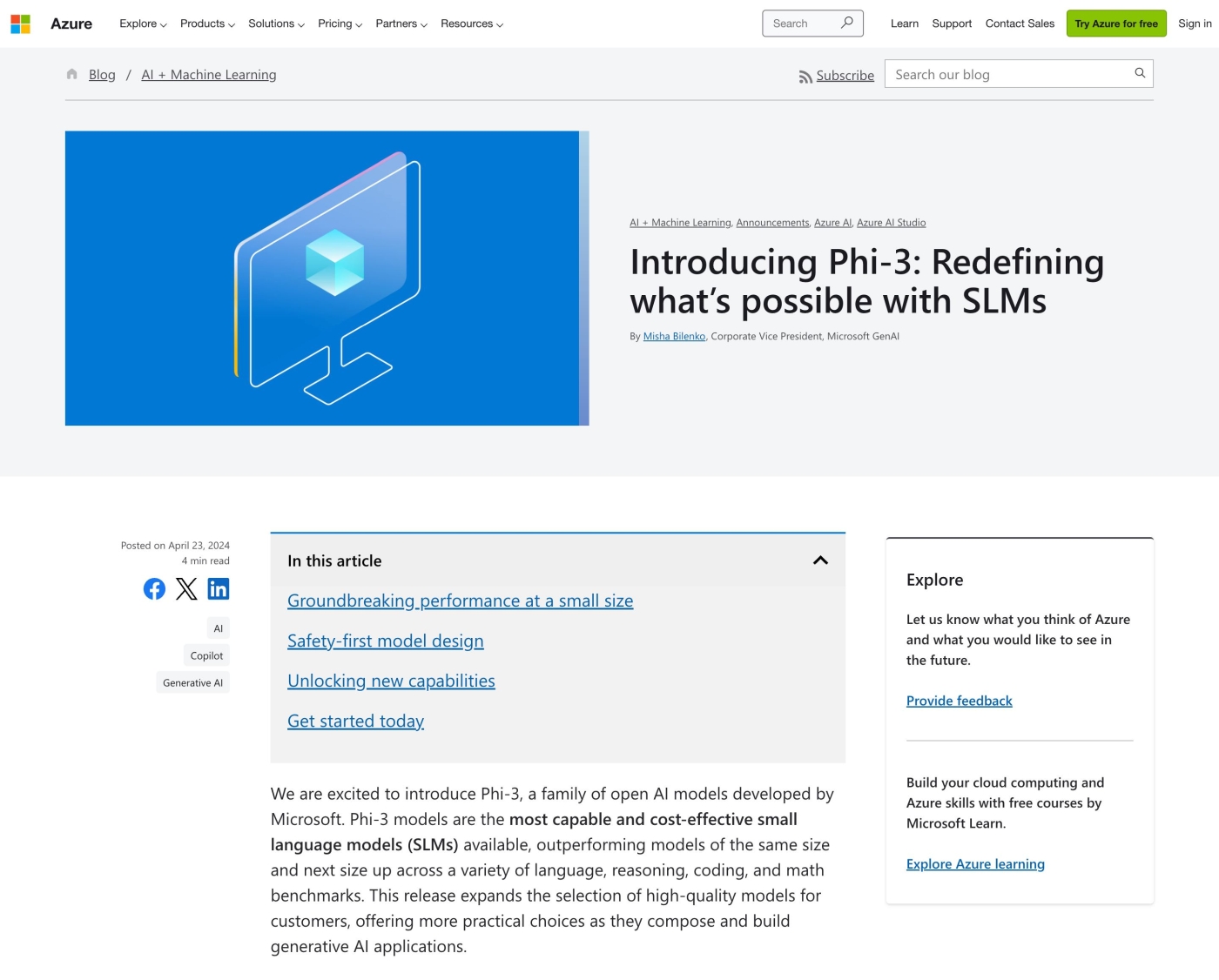
図7 4月にMicrosoftが発表した、SLM(小規模言語モデル)「 Phi-3 」 。最も小さい「Phi-3-mini」のトレーニングデータは38億パラメータ(比較例:「ChatGPT-3.5」のパラメータ数は3,550億)と小さいが、同サイズのLLM(大規模言語モデル)よりも高い性能を持つ。スマートフォンなどのモバイル端末のローカル上で動作して、オフラインでも利用が可能 今年は各メーカーから、AIプロセッサーやAI機能を組み込んだスマートフォンやPCの市場投入が発表されています。身近なデバイス上だけでAIを動作させる「オンデバイスAI」が一般的になれば、外部に出せない個人や企業のデータの利用も拡大していくはずです。
AIの利用がより幅広い層へと広がれば、市場も拡大します。直近の米国の大手IT企業の決算発表では、AIに対する投資額はまだまだ増加しており、今年は生成AIがより手軽で身近なものになると考えています。
一貫性が生み出す、生成AIの問題点
誰もが手軽に生成AIの利用ができることは、大きなメリットです。ただし、利用者の増加とともに、デメリットの増加も予想されます。
中でも、画期的な技術といえる「一貫性の維持」の進展は、大きな問題点も生み出しています。それが、本物と見分けがつかない画像や動画を使ったディスインフォメーション(信用を失わせる目的で故意に流される虚偽情報)です。
2016年のアメリカ大統領選挙では、「 フェイクニュース」と呼ばれる誤った情報が、SNSを中心に拡散されて大問題になりました。当時は文字を中心とした情報の拡散でしたが、現在では生成AIの登場で、生成された画像や動画、音声などが悪用される可能性があります。
今年11月には、4年に一度のアメリカ大統領選挙を控えています。そのため、投票日が近づくにつれて、ディープフェイク(生成AIなどを利用した偽物の画像や動画、音声)に対する警戒感が高まっています。
すでに生成AIによる画像や動画は、本物か偽物かを判断できない品質にまで近づいています。こうした懸念から、紹介した「Sora」のように、一般公開を遅らせている生成AI系の技術も少なくありません。
州によっては、政治広告へのAI使用の明記を義務付ける法案が審議されるなど、規制も進んでいます。また、生成AIモデルを開発している企業では、生成AIで制作されたものかを判別できるツールの開発も進んでいます。
動画5 Google DeepMindが発表した、生成AI画像識別ツール「SynthID」。画像内に肉眼では見えない電子透かしを埋め込む。フィルターやトリミング、ノイズの追加などの修正を加えても、透かしが検出可能。VIDEO
選択肢が増えつつある、学習データへの対応
生成AIの登場時から議論の対象となっている、AIモデルの学習データについての対価問題も未解決です。法的には、インターネット上での学習データの無断収集は問題ないとされています。しかし、著作権物を保持する企業からは、生成AIの学習データとして利用する企業に対して、正当な対価の支払いを求める訴訟も発生しています。
こうした問題を受け、OpenAIのようにデータを持った企業に対して対価を支払い、双方合意の上でAIの学習データとして利用できる契約を結ぶ事例も増えています。
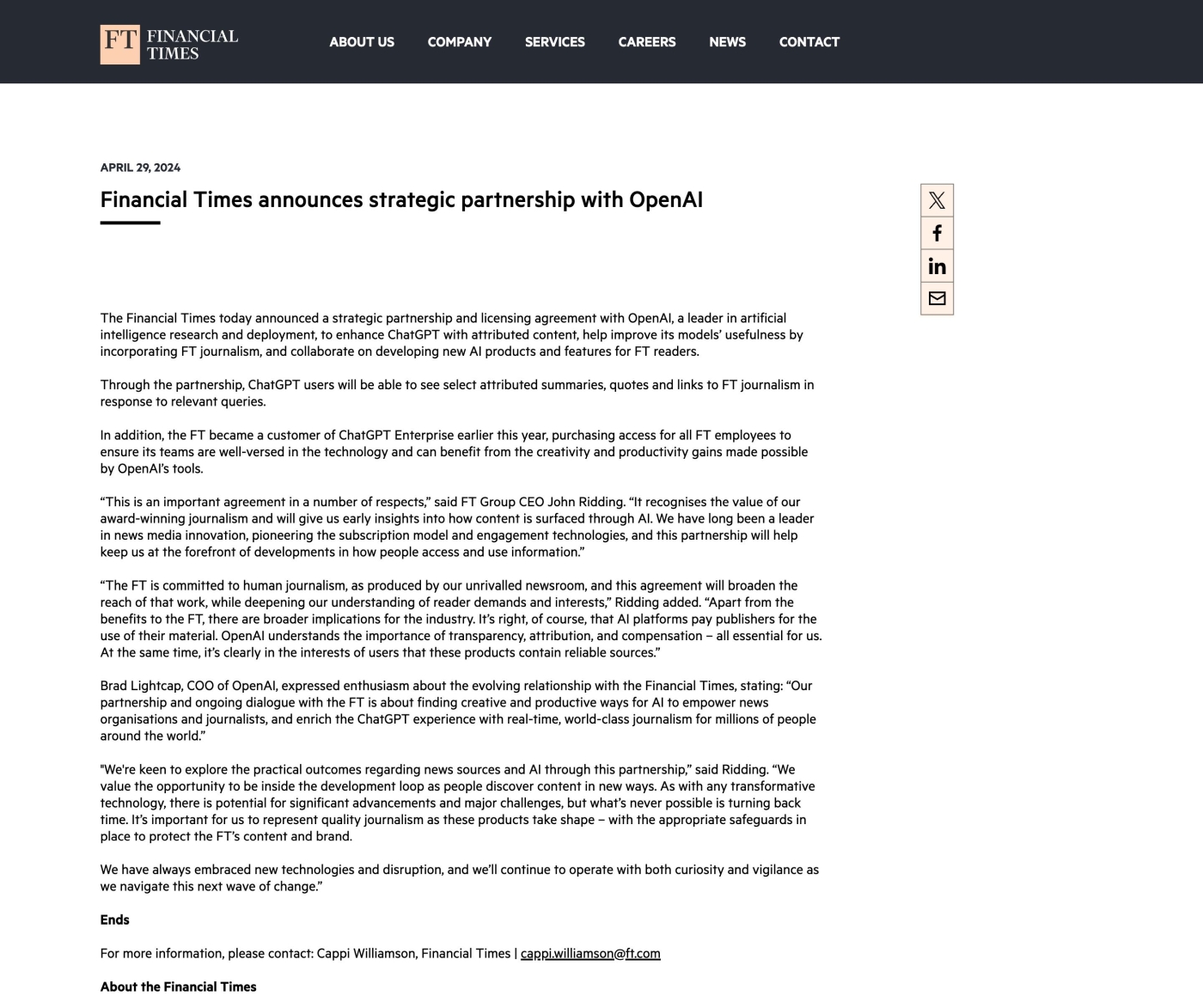
図8 4月29日に発表された、Financial TimesとOpenAIとの戦略的パートナーシップ、およびライセンス契約の発表 。ここ半年間に、OpenAIはドイツのアクセル・シュプリンガーやフランスのルモンドなど、大手メディア企業と著作権を持つ記事をAIの学習に使用できるライセンス契約を次々と行っている もうひとつ、同様に生成AIの登場時から発せられていた、各種クリエイターからの「自分の作品をAIの学習データに使用されたくない」という要望も未解決です。自由な作品公開をためらい、不本意にも作品をインターネット上から取り下げるクリエイターが出てくるなど、実害も出ています。
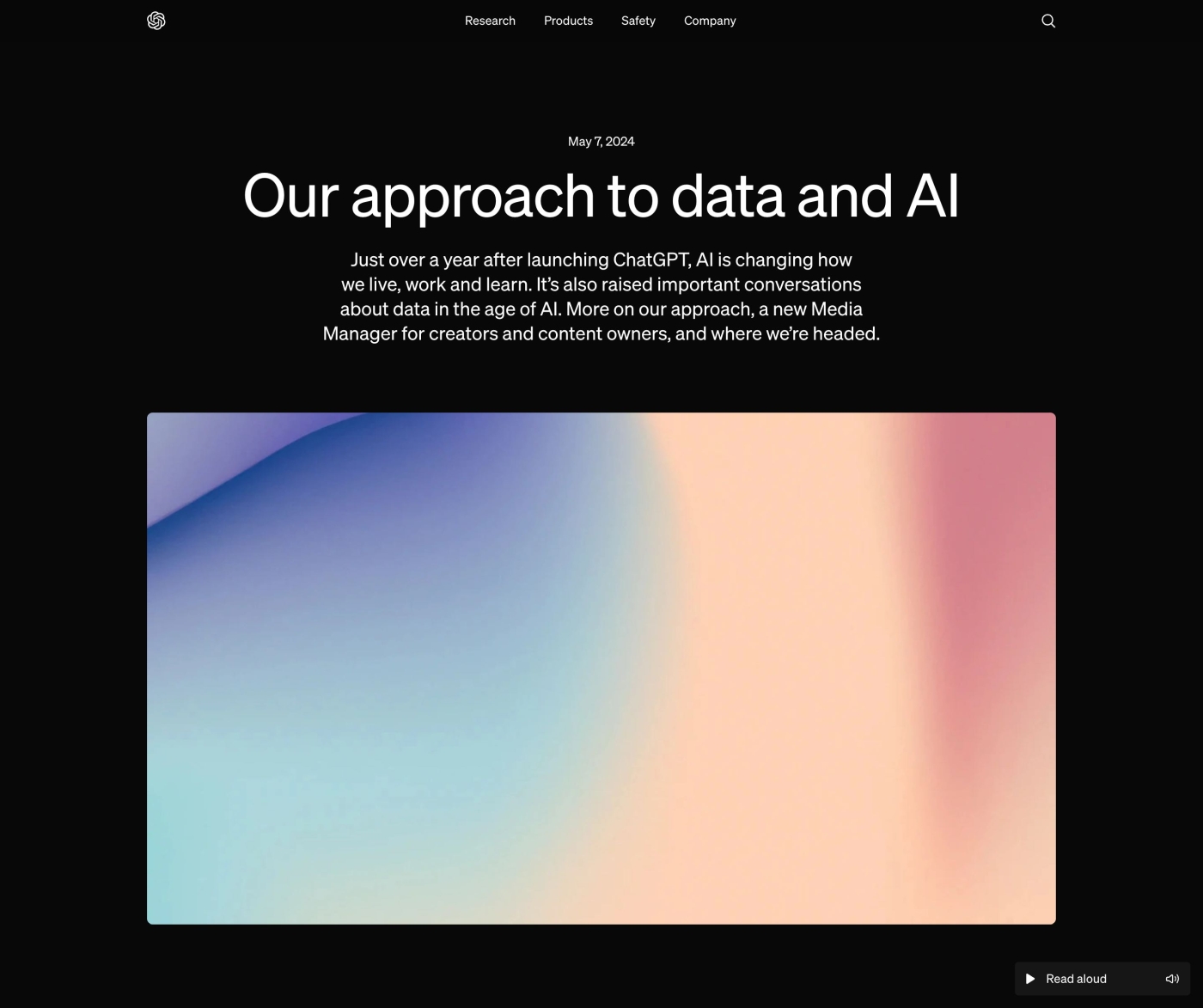
図9 5月にOpenAIは、クリエイターやコンテンツ所有者向けのツール「Media Manager」を開発中と発表。クリエイターが、自分のコンテンツをOpenAIの学習から除外するよう指定できる 選択肢としての「AI学習拒否」機能の実装を含め、生成AI側の対応と問題解決が求められています。ようやくOpenAIが学習データへの除外申請ができるツールの開発を発表するなど、少しづつではありますが、クリエイター側の選択肢を増やす方向へと動き始めています。
まとめ
生成AIにおける大きな課題だった「一貫性の保持」と「生成の高速化」は、新たな技術によって解決されてきました。動画生成AIが登場したように、新しい技術を基盤としたサービスやAIモデルが今後も登場するでしょう。
今年は生成AI対応のデバイス登場や、ローカル上で動作する「オンデバイスAI」が拡大することで、誰もが手軽に生成AIを利用できる環境も整って、より身近なものとなるでしょう。
生成AIに関する技術の発展で、ディープフェイクなどの深刻な問題点も浮き彫りとなりました。問題解決のため、生成AIを使った生成物へのラベリングの明示化や義務づけなど、規制や法整備も大きく進展すると予想しています。
どの大手IT企業も、生成AIへの積極的な投資を継続中です。いずれビジネスとしての損益分岐点を探る時期がきますが、少なくともここ数年は、投資減少の気配はありません。大手IT企業を中心に、これからも画期的な生成AI関連の技術が登場することになりそうです。
編注・追記:2024年5月22日
Open AIは5月21日、 今週開催のAI Seoul Summitに向けて「OpenAI safety update 」を掲載しました。画像生成を含む生成AIに関する安全性について最新の状況を説明しています。