概要
まいにち使っている検索エンジンがどうやって動いているか,知っていますか?
本書では,小さな検索エンジンを作りながら,ソースコードレベルで検索エンジンのしくみを解説。
Yahoo!Japanの検索エンジン開発チームを経て2008年度上期未踏IT人材発掘・育成事業において高性能分散型検索エンジンの開発によりスーパークリエータに認定された山田浩之氏と,全文検索エンジンSenna/Groongaの開発に携わってきた末永匡氏による,オンリーワンの1冊です。
こんな方におすすめ
著者から一言
本書は,GoogleやYahoo!などのウェブ検索サービスの裏側の検索エンジンというシステムに焦点を当て,その内部のメカニズムを明らかにしていきます。まず第1章で,検索エンジンの基礎および原理をしっかり学んでいただき,第2章以降で,サンプル検索エンジンのソースコードを用いて検索エンジンの開発を体験していただきます。このような原理と実践のバランスにより,読者のみなさんが検索エンジンの仕組みをより深く理解することを目指しています。
原理と全体の構成および監修は企業や大学で検索エンジンの研究開発をしてきた山田が担当し,実践および運用におけるポイントはオープンソース検索エンジンSenna/Groongaの開発者であり実際に多数の検索サービスの運用経験を持つ末永さんが担当することにより,このようなバランスを実現することできました。
本書によりみなさんが得た知識や経験が,画期的なソフトウェアやサービスを生み出す1つのきっかけとなれば幸いです。
目次
第1章 検索エンジンはいかにして動くのか
1-1 検索エンジンの構成を理解する
- 検索エンジンとは
- 検索エンジンを構成するコンポーネント
- 検索エンジンに関連するコンポーネント
1-2 高速な全文検索を実現するインデックスの仕組み
- 全文検索の2つの方法
- 転置インデックスの仕組み
- 転置インデックスの作り方
- 転置インデックスで用いられる用語
1-3 転置インデックスを深く知る
- 転置インデックス=辞書+転置リスト
- 転置インデックスから単語を探す
- 転置リストに単語の位置情報を加える
- 転置インデックスからフレーズを探す
1-4 日本語文書から転置インデックスを作る
1-5 転置インデックスの実装
1-6 転置インデックスを用いて検索する
- ブーリアン検索
- 転置インデックス用いた検索処理の流れ
- 関連度の計算方法
- 情報検索における検索
1-7 転置インデックスを構築する
- メモリを用いた転置インデックスの構築
- 二次記憶を用いた転置インデックスの構築
- 静的なインデックス構築と動的なインデックス構築
1-8 検索したい文書を用意する
第2章 全文検索エンジンのサンプルを準備する
2-1 全文検索エンジンwiserの概要
2-2 wiserをセットアップする
- wiserをビルドする
- wiserを起動する
- Wikipediaデータを展開する
2-3 wiserを動かす
- 転置インデックスを構築する
- 転置インデックスを用いて検索する
- grepとwiserの実行速度を比較する
第3章 転置インデックスを作ろう
3-1 転置インデックスのおさらい
- トークンを抽出する
- トークンごとにポスティングリストを作る
3-2 転置インデックスを構築する
- ストレージ上でポスティングリストを作る
- ポスティングリストと転置リストのデータ構造
- 転置インデックスの構築手順をソースコードレベルで追う
- ソースコードをより詳細に見る
- コラム 要件に応じた検索エンジン(システム)の設計
第4章 検索しよう
4-1 検索処理のおおまかな流れ
4-2 転置インデックスを用いて検索を行う
- 検索処理をソースコードレベルで追う
- 関数split_query_to_tokens()の内部を読み解く
- 具体例を用いて検索処理の流れをより深く理解する
- 関数search_docs()の内部を読み解く
- 関数search_phrase()の内部を読み解く
- コラム タグ検索はどのように実現されるか
第5章転置インデックスを圧縮しよう
5-1 圧縮の基本
- 転置インデックスにおける圧縮のメリット
- コラム 圧縮の目的
- 転置インデックスの圧縮方法
- 転置リストの圧縮方法
- なぜ圧縮できるのか
5-2 wiserにおける圧縮機能の実装
- 圧縮機能のソースコードの概要
- 圧縮しない場合の動作を見る
- Golomb符号の概要を把握する
- Golomb符号における符号化の処理を読み解く
- Golomb符号における復号の処理を読み解く
第6章 wiserの改良やパラメータの調整に挑戦してみよう
6-1 検索処理を効率化する
- 改善のポイント
- 検索クエリを重複しないトークンに分割する
6-2 フレーズ検索をやめてみる
- 2文字の文字列を検索したときの挙動を調べる
- 3文字の文字列を検索したときの挙動を調べる
6-3 検索結果の出力順序を変更する
- 検索結果の並び替えの軸となる指標
- 検索結果を文書サイズの大きい順に出力する
- コラム ランキングSPAM
6-4 1文字の検索クエリで検索できるようにする
- 特定の文字を接頭辞に持つトークンの一覧を取得する
- 検索して結果をマージする
- コラム 類似文書検索を実現するには
6-5 転置インデックスの更新バッファ量を変えてみる
- バッファサイズの違いによる効果の差を確認する
- sarコマンドで負荷を調べる
6-6 英字アルファベットだけトークンの分割方法を変えてみる
- 英単語の検索で適合率が下がる問題を避けるには
- インデックスの対象にする文字をどう判定しているか
- トークンの分割を行う関数を修正する
6-7 圧縮の効果を確認する
- Golomb符号の効果を見る
- 非圧縮時と圧縮時のインデックスサイズを比較する
- コラム 全文検索エンジンの安易な利用を避ける
第7章 これからより深く学ぶために
7-1 wiserでは扱えなかったテーマ
- 転置インデックス以外の全文検索インデックス
- 大規模なデータを効率よく扱えるストレージ
- キャッシュを利用した高速化
- さまざな圧縮方法の利用
- ランキングの改良
- 適合率と再現率の調整
- 検索結果の並び替え処理の負荷を減らす
- 並列処理
- 属性による絞り込みとの併用
- ファセット検索
- コラム レイテンシとスループット
7-2 全文検索エンジンGroongaでの工夫
- トークンの部分一致検索による再現率の向上
- メモリマップトファイルの利用
- スニペット
- コラム 広報活動の大切さ
7-3 利用者の意図を考慮した検索エンジンを目指して
- ストップワードを導入する
- 形態素解析のミスに対処する
- コラム ぎなた読み
- 組文字・全半角を扱う
- ひらがな・カタカナを同一視するどうか判断する
- 表記のゆれを考慮する
- 検索クエリを正規化する
- ブーリアン検索の解釈に気をつける
- 検索クエリを形態素解析器により適切に解析する
- 誤り訂正を行う
- 入力を補完する
- 関連する検索キーワードを提案する
7-4 文書の収集・抽出におけるポイント
- クローラを作るうえで対処すべきポイント
- テキストの抽出で対処すべきポイント
Appendix
A-1 高度な話題
- 近年の圧縮手法
- 動的なインデックス構築
- インデックスの分散
A-2 wiserのテキスト抽出・保存処理
- XMLを扱う2種類のAPI ~DOMとSAX
- 文書のタイトルと本文を取り出す
- 状態を把握する
- 文書データベースを構築する
サポート
ダウンロード
本書のサンプルファイルは,以下のリンクよりダウンロードできます。
- ダウンロード
- wiser-20140928.tar.gz
ファイルをダウンロード後,適宜解凍してご利用ください。
また,本書で利用するWikipediaのデータは以下のリンクからダウンロードできます。
http://dumps.wikimedia.org/jawiki/
正誤表
本書の以下の部分に誤りがありました。ここに訂正するとともに,ご迷惑をおかけしたことを深くお詫び申し上げます。
(2015年11月4日更新)
P.20 表1-3見出し
P.23 「転置インデックスから単語を探す」9行目
| 誤 |
各ポスティングリストが含まれる文書IDの共通集合を取ればよいのです。 |
|---|
| 正 |
各ポスティングリストに含まれる文書IDの共通集合を取ればよいのです。 |
|---|
P.27 小見出し
| 誤 |
N-gram(q-gram)よる分割 |
|---|
| 正 |
N-gram(q-gram)による分割 |
|---|
P.32 図1-5 一番左の枠
P.42
| 誤 |
最初に、文書ごとにレコード<単語、文書ID、文書における単語のTF>を生成し、
|
|---|
| 正 |
最初に、各文書において、当該文書を構成する単語ごとにレコード<単語、文書ID、文書における単語のTF>を生成し、
|
|---|
P.42 リスト1-4 5行目
P.42 ①の示す範囲
| 誤 |
5行目のみ
|
|---|
| 正 |
4行目から6行目(for all word∈ d do ~ end for)
|
|---|
P.46 最終行
P.54 「Debianの場合」の実行例
| 誤 |
> aptitude install build-essential sqlite3 libsqlite3-dev bzip2
|
|---|
| 正 |
> aptitude install build-essential sqlite3 libsqlite3-dev libexpat1-dev bzip2
|
|---|
P.55 1行目
Bは小文字が正しいです。
P.57 1行目
※先頭のwは大文字
P.57 下から4行目
P.58 2つめの実行例
| 誤 |
articles
.xml |
|---|
| 正 |
articles.xml |
|---|
「articles」の後ろに改行が入らないのが正しいです。
P.58 実行例2
| 誤 |
jawiki-●●●●●●●●-pages-article.xml
|
|---|
| 正 |
jawiki-latest-pages-articles.xml
|
|---|
P.58 最終行
| 誤 |
time grep 'Wikipedia' jawiki-latest-pages-articles.xml
|
|---|
| 正 |
time grep 'Wikipedia' 1000.xml
|
|---|
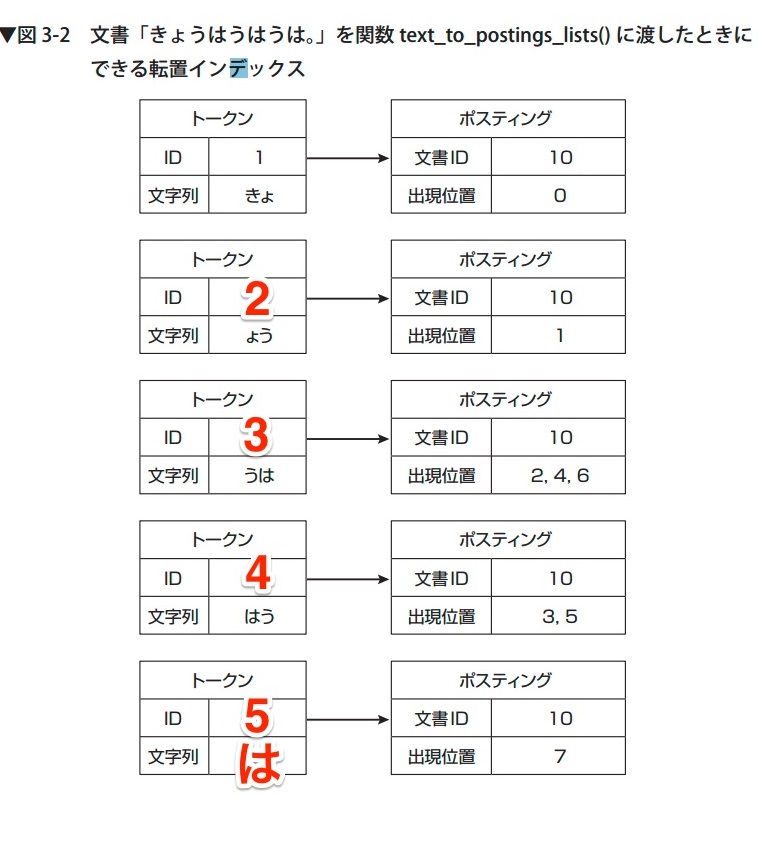
P.73 9行目および図3-2キャプション
末尾の句点が不要です。
P.73 図3-2
以下の図のようになります。図をクリックすると大きく表示できます。
P.106 2行目
| 誤 |
10 = 5 × 1 + 4
|
|---|
| 正 |
9 = 5 × 1 + 4
|
|---|
P.140 下から3行目
P.162 図7-1の「適合率」の説明
P.162 図7-1「再現率」の説明
P.170 コラム1行目
P.173 本文9行目
「何」の後ろの「ら」が入らないのが正しいです。
P.176 下から3行目
P.181 本文2行目
P.189
※「(参考文献7)」削除
P.191 下から5行目
