2021年8月に発売される『機械学習を解釈する技術』 『施策デザインのための機械学習入門』 安井翔太氏の3人による対談を3回にわたってお届けします。第1回は、書籍執筆のモチベーションのお話から。
それは個人的な興味から始まった
安井: では僕から振ったほうがいいでしょうか。じゃあとりあえず執筆のモチベーションと裏話みたいなところから伺っていきたいのですが。
安井翔太(やすいしょうた) 2013年にNorwegian School of Economicsにて経済学修士号を取得しサイバーエージェント入社。入社後は広告代理店にて広告効果検証等を行い、その後2015年にアドテクスタジオへ異動。以降はDMP・DSP・SSPと各種のアドテクプロダクトにおいて、機械学習に関する業務やデータを元にした意思決定のコンサルティングを担当。現在はAILabの経済学チームのリーダーとして経済学と機械学習の融合に関する研究を行う一方で、Data Science Centerの副所長として社内のデータサイエンスプロジェクトのコンサルティングも担当。著書に『効果検証入門』( 技術評論社、2020)がある。
森下: しゃべりだしが一番難しいですね。執筆のモチベーションですか……。なんというか、僕は「機械学習でただ予測して、なんだかよくわかんないんだけどまあなんか予測ができます」みたいなのがすごく嫌でした。もともと計量経済学からデータ分析の世界に入ったからかもしれないんですが、なぜそういう予測をしてるんだろうとか、モデルの振る舞いををいろんな視点から確認して、大丈夫そうだということを認識して使いたいなみたいな気持ちがあります。
なので、機械学習は解釈性が低いと思っていたためあまり好きではなかったのですが、あるとき機械学習の解釈性の存在を知って、すごく面白いなと思っていろいろ勉強しました。今はIMLの日本語訳が出た と思うんですけど、当時はわかりやすい日本語の説明や書籍は少なかったので、自分でブログを書いたりとかもしました。そういう発信をしているうちに執筆のお声がけをいただいいたので、ぜひ!という感じで書かせていただいてるという流れです。
安井: なるほど。ありがとうございます。予測モデルの妥当性を解釈性から検証するというところをスタート地点にしたんですね。
齋藤: 個人的な興味発信で勉強しはじめたという感じなんですか?
齋藤優太(さいとうゆうた) 2021年に、東京工業大学で経営工学学士号を取得。大学在学中から、因果推論と機械学習の融合技術(反実仮想機械学習)や、バイアスを含むユーザの行動ログに基づく推薦・ランキング学習に関する研究を行う。その過程で、ICML・RecSys・SIGIR・WSDM・SDMなどの機械学習・データマイニング領域におけるトップレベル国際会議にて査読付論文を発表。2020年には、半熟仮想株式会社を共同創業。以降当社の科学統括として、複数の国内テクノロジー企業との共同研究の取りまとめを担当、専門技術の社会実装や大規模実証研究に取り組み、その研究成果の一部が日本オープンイノベーション大賞・内閣総理大臣賞を受賞。2021年秋からは、Cornell University、Department of Computer Science(Ph.D. program)に進学し、関連領域の研究を継続する。
Twitter:@usait0 usaito.github.io
森下: もともとは個人的な興味ですね。最初から実務で必要だったというわけではないです。調べるうちに、できることがいろいろわかってきたので、実務に使えそうなものを使い、逆に実務で必要な解釈性を与える手法はないか勉強したりしています。
安井: 森下さんの書かれているブログ記事などを読んだ際に、在籍されてる会社的に 絶対実務から来ているんだろうなぁって勝手に思ってました。
森下: なるほどなるほど。実務ではそもそもinterpretability(解釈性)の高いモデルを使った方がいいという話も当然あると思っていて、ブラックボックスモデルじゃなくて線形モデル使えばいい、みたいな話も結構あると思いますね。
安井: 今回書かれた書籍の中だと、予測モデルのバリデーション以外にも結構いろんな使い方があるよね、といった紹介をされていたと思うんですけれど。本を執筆していく過程で、違う使い方を実務でも始めたりしたんでしょうか? たとえば、書籍の中で因果関係の探索のために使うのが良いんじゃないかと書かれていて、結構面白いなと思ったんですけど。そういう使い方を実際にしたのかなって気になっていて。
森下: それはそうですね。統計モデルを作るときは背後のメカニズムみたいなものを考えて特徴量を吟味したりすると思うんですけども、機械学習モデルを使うときってバーッと特徴量を入れて、それで予測モデルを作ってみる、みたいなことが多いのかなと思っています。で、それを機械学習の解釈手法で実際に解釈してみるとある特徴量の重要度が高いだとか、ある特徴量とアウトカムには一定の関係がありそうだということが分かったりします。ただ、これが必ずしも因果関係を意味するかっていうと、厳密にはそうではないので、因果関係の探索ののために利用する、みたいな使い方がいいんじゃないかと思っています。
安井: なるほど。モチベーションの話からもうちょっと広げてみると、因果関係の話が出てきたと思うんですけど、解釈性の話を書かれてる記事や書籍の中で、因果関係として解釈するのは難しいっていうのを警告しているのは珍しい気がしています。
森下: そうですか。
安井: その感覚が合ってるのかなっていうのと、そこを強調した理由はありますか。
森下: 強調した理由といえば、…そうですね、せっかくモデルが何をやってるかをできるだけ正しく理解しようという手法を使っているにもかかわらず、その解釈を間違っているのではあまり良くないと思っています。モデルの限界を知るのと同じように、解釈手法の限界もある程度知っておく必要があると思います。因果推論でも、「 どういう状況のときに効果を識別できます」みたいな話を理解せずに適当にやっちゃうと良くないという話と一緒だと思います。なので、機械学習の解釈手法についてもある種の限界みたいなものはお伝えしたいなと僕は思っています。
安井: ありがとうございます。
森下: やっぱり根本的な思いとして、因果関係を本当に知りたかったら、因果関係がわかるような手法を直接使えばいいというのがあります。機械学習の解釈手法は、機械学習モデルを作ったときにそれを頑張って解釈しよう、という営みなのかなと思っています。
また、便利なものを紹介したいというのがモチベーションにあったかもしれません。便利なのでみんな使ってみてくださいとか、便利だけど中身よくわからないで使っている人がいるかもしれないので、わかるように説明したいとか。そういうモチベーションがあったと思います。
中途半端な立ち位置の自分だから書けるもの
安井: なるほど、ありがとうございます。続いて齋藤さんに今回の執筆のモチベーションをお聞きしたいです。
齋藤: そもそも執筆に至った経緯は、1年半ぐらい前なので忘れかけているところもありますけど。もともと安井さんと谷口さんと一緒にCFML勉強会をやっていた時期、オフラインで頻繁に開催していた時期と、安井さんが『効果検証入門』 たぶんその流れで、CFMLみたいなものを続刊で出してみないかみたいな話があって、1年ちょっと前の2020年4月ぐらいに書き始めたという感じですね[1] 。
最初はあまり自分の中で企画が固まってなくて。いわゆるクラシカルな因果推論でいうと、それこそ安井さんの本とか、それ以外にもいくつか実務というよりもメソッドにスポットライトを当てた本が日本語でもあると思うんですけど、機械学習と因果推論の融合とか、反実仮想機械学習(CounterFactual Machine Learning;CFML)( ※2 )に関する本がないので、それを書いてみようみたいな、やんわりとしたところで始まったっていうのが経緯かなと思います。
そうして書き始めたうちに内容が自分のわがままで変わっていってしまったんですけど、CFMLの本というよりはもうちょっと一般的な機械学習について、「 実務で使うときは本来こう考えるべきだし、こういう手順をとるべきなのに、みんな結構素通りしちゃってる。でも素通りしちゃうと結構危ないですよね」といった、より根幹の話(機械学習のフレームワーク)を書いた方がインパクトが大きくなると思って、徐々にそちらに舵を切っていったというのが、私の執筆のモチベーションに関わる話なのかなと思います。
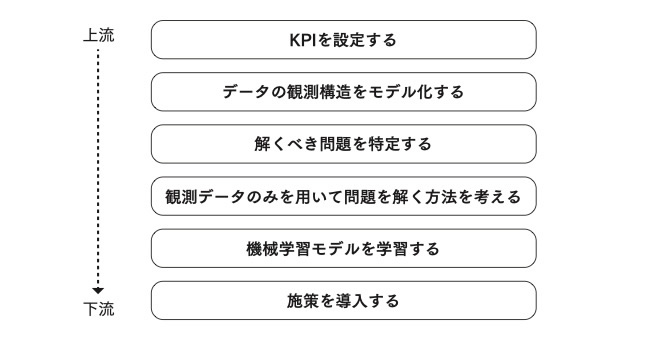
機械学習実践のためのフレームワーク(『 施策デザインのための機械学習入門』第1章より)
齋藤: たとえば、IPS(Inverse Propensity Score)を機械学習と組み合わせたらこういう使い方です、といったよくある単純な手法の話は別に自分が書かなくても適任が他にいると思います。そういった単に手法の定義や性質、こういうふうにワークしますっていう話だったら、自分じゃなくても書けるだろうなって思ってしまうんですよね。
できるだけ自分にしか書けなさそうな話を書きたい、という気持ちと並行して、機械学習を実務で使っていて論文も定期的に読んでます、みたいな人たちとこれまで会話してきた中で、自分が思っている機械学習のフローと、そういった人たちが考えているフローや見ている機械学習像みたいなところが結構違うんだろうなって、なんとなく思っていたんです。それを言葉で書き起こした本が日本語・英語含めて無いなと思っていたのが執筆開始のタイミングと合わさって、それを自分で書いてみたいなと思いはじめました。
一応この本に分野を割り当てるとしたらCFMLになると思うんですけど、CFMLは手法というより考え方の分野っていうか思想の分野だと思っていて、その分野の根底にある思想を一般的な機械学習に関する話の中に自然に組み込むという挑戦を、面白がって勝手にしていましたね(笑) 。
誰でも書けそうな、自分が書かなくてもよさそうな本じゃなくて、中途半端な位置にいる自分だからこそ書けそうな本、プラス、もともとあった機械学習の実践って本来こう考えるべきでしょって自分が思うフローのあたりをうまく掛け合わせると、ちょうどいい本になるのかなという感じでしょうか。
安井: ありがとうございます。そうですよね、そこのフローの食い違いの部分がたぶんこの本のメインテーマの1つになってて、どういうきっかけでそこの食い違いに気が付いていったのかなっていうのは、詳細に知りたいなとか思っているのですが。
齋藤: いや、それは自分も知りたいですよね(笑) 。あまり明確なきっかけがあったわけじゃなくて、本当に徐々にというのが正直な感覚です。
3人: (笑) 。
齋藤: 勉強会もそうですし、自分でデータをさわったりしないにせよ、ミーティングに参加していろんな実務に近い話をして、論文も自分で書いているという中途半端なポジションにいると自分では思っていますけど、意外とそれは面白い立場にいるとも思います。たとえば今回の書籍は一応最新の研究の流れを踏まえているので、実践者の人にはなかなか書けないと思うんですが、同時に理論ですごい頑張っている研究者の人でも意外と書けない話なんだろうと思っているんですよね。
研究者の目線で言うと、機械学習に対してそういう見方をするのは別に当たり前な反応だと思うんですけど、研究者にとっての当たり前を実践者にとってすんなり受け入れられる文章にまとめるのは、研究者は意外と得意じゃないと思っているんですよ(笑)。そこを今回は実践者にとってすんなり頭に入る流れに落とし込むよう意識して書いてました。自分でもうまくできているかわからないし、そこは安井さんの全体を読んだ感想を今ききたいんですけど。実践にも研究にもある程度顔突っ込んでる中途半端なポジションにいるからこそ書けるとう意味では、最初の話とつながっていて、他にあまり適任がいないんじゃないかなという文章にはなってると思います。
まだ本がどのように受け入れられるかわからない時点で、自分でもあまり自信をもって言えないところではあるんですけど。自分では面白いストーリーに落ちていると思いますし、「 これと同じ話を書ける人が誰かいそうか?」っていうのが自分の中ではパッと思い浮かばないというのをひとつの基準として、それに当てはまる話を意識して書いていた感じですね。
執筆の分担とイメージ共有の難しさ
安井: ありがとうございます。森下さんから何かありますか? 齋藤さんに聞きたいこととか、気になってる内容とか。
森下: (執筆の)分担はどういうふうにされてたんですか?
安井: 最初は僕は1章、1つの章を担当するって感じだったんですけど、方針を変えるっていうタイミングで僕は完全に金魚の糞になったっていう感じです(笑) 。
森下: あはは、なるほどなるほど。ありがとうございます。
齋藤: 結構そこは難しくて、裏話に入る気もしますが。本職で本を書いてる人たちが複数人が集まってチームを組むことになったら、時間をかけて密にイメージ共有をしてじっくり書けるんだと思います。一方で、今回はそれぞれ別に本業があって、その中で副業として本を書いてるじゃないですか。少なくともここにいる人たちはそうだと思うんですが。そうなると頻繁にイメージ共有とかができない状況が難しい点としてありました。それに最初から複数人の中でイメージ共有ができてしまっている話は、さして新しい話ではないと思うんですよね。
安井: なるほど。
齋藤: 自分の頭の中にあった話っていうのは、なかなかイメージ共有が難しいところがあったので、今回は途中から自分ひとりが頑張って書いたという経緯があります。まあそこは、自分がイメージ共有をさぼったというのもあるのですが。そこをうまく複数人でまわすにはどうしたらいいのかなっていうのは本の内容と別のところで考えていて、難しいと思った点ですね。普段、ブログ記事を書くときも、同じ話題でもこういう説明の仕方をしている記事がないなっていうのを書くのが好きなので、そういう個人の好き嫌いもあって、わがままをさせていただきました。
森下: なるほど。ありがとうございます。
齋藤: 明確に書きたいものはあって、文章を見たときにこれは合ってるとか、これは合ってないとか判別はできるんですけど、それをうまく言語化して事前に伝えるのがなかなか難しいんですよね。自分がまだ単に経験がないのか、そういうイメージ共有に長けてないのかわからないのですが、今回はちょっと力業で押すみたいな感じで突っ走ってしまいました。
3人: (笑) 。
安井: 何か月前かな、NHKでシン・エヴァンゲリオンの庵野監督の特集をやってて、庵野監督が下の人からアイデアをどんどんもらって、「 これじゃないことはわかった」って言い続けるっていう場面があって、これと似てるなーって思いました。
齋藤: そうなんですね。あのドキュメンタリーは自分も見たいなと思ってたんですが結局全然見れてなかったです(笑) 。なるほど。あれ、何の話でしたっけ?
安井: モチベーションです。もともとのストーリーは。
齋藤: 話はずれるんですけど、今回は研究的な新規性はないんですけど、説明や導入の仕方が新しいというか、そういう文脈で語ってる人はいないよねみたいなところに関してある程度自信というか見立てはあるので、やっぱりそういう話を考えて書くのは結構好きだなーって確認は今回の経験を通じてできました。体力的にはつらかったんですけど、こういう活動は好きだなーっていうのを確かめるきっかけにはなったなと思います。
モチベーションとか自分の思考というか、何を面白いと思うかということに依存している本だと思います。前に海外大学院留学の経緯に関するブログも書いたんですけど 、これもそういうモチベーションで書いてるという感じですね。留学に関するブログは他にもたくさんあるんですけど、自分のブログの方では、これまでにあまり書かれてなさそうな話を書いてみました。
安井: 感想の話がさきほどありましたが、僕は読んでて学会のチュートリアルが本になったなって感覚がありましたね。
齋藤: 今度アナウンスがあるんですけど。実は今年、国際会議でチュートリアルをやるんですよ。
安井: すごい。
齋藤: 私のTwitter を見ておいていただけたらなと思います。
3人: (笑) 。
齋藤: 応用系の学会のチュートリアルなら今回の本と雰囲気が似ているのかもしれないですね。ただKDDとか有名な因果推論のチュートリアルがあると思うんですけど、あれは実務寄りのストーリーというよりは、普通に因果推論のメソッド紹介って感じだったと思うので、別に意地をはってるわけじゃないんですけど、今回の本の雰囲気とはちょっと違うかなっていう印象はあります。
安井: 『Trustworthy Online Controlled Experiments』
齋藤: はいはいはい。
安井: あの本を書いた人のA/Bテストのチュートリアルはすごく実践的です。その機械学習版みたいな感じがしますね。
齋藤: あー。あのチュートリアルまではあまり追い切れていないですね。まあ今度の自分が開催するチュートリアルは本の雰囲気とは違って単にメソッドの話をする予定なんですが。
3人: (笑) 。
(第2回へ続く)