分散型SNSソフトウェアMastodon(以下マストドン)。OSSであることから、いくつものサーバー(Mastodonではインスタンスと呼ぶ)が立ち上がっています(マストドン自体については、連載「Mastodonを楽しく歩こう」も参照してください)。
そしてpixivが企業として一早く、マストドンのインスタンスを「Pawoo」としてリリースしました。構築開始から10時間でリリースされ、現在も速いスピードで開発が続いています。そのようななか、4月25日、pixiv社にて「Mastodon/Pawooの運用&開発技術 - pixiv Night #04」が開催されました。本稿ではこの模様をレポートします。

司会進行は川田さん(@furoshiki@pawoo.net)。pixiv Nightが、社内プロダクトなどで使っているテクノロジーや技術的な話を外部に発信していくイベントであるとし、今回のテーマが「マストドン・Pawoo」であると説明しました。
マストドンが流行り始めたなかで、企業では最速となる4月14日にリリースしたPawoo。このPawooのプロジェクトと開発について、pixiv社の開発陣が発表していくと話しました。

「今後のPawooとか?」
最初の発表は、Pawooをやろうと言い出し、現在Pawooのプロダクトマネージャーでもある、清水さん(@norio@pawoo.net)。勢いで始まったPawooですが、かなりの反響があるため、「pixivとしてやっていくべきではないか」ということで、全員でがんばっているところだと言います。

マストドンの面白さとは何か?
はじめに「マストドンの面白さは何か?」について説明がありました。
マストドンの設計思想は、脱中央集権を狙った分散型SNSのOSSです。様々な人がインスタンスを立てて、そのインスタンスごとのルールに共感した人がそのインスタンスに参加して、コミュニケーションしていきます。
清水さんは、このことが根幹だとしながらも、副次的な機能として一番面白く感じたのが、インスタンスごとのローカルタイムラインだと言います。これまでも違うサービスなどで似たようなものがありましたが、それらとの違いはリアルタイムなコミュニケーションができるものではなかったことです。
初期のツイッターではすべてのつぶやきが見えるパブリックタイムラインがありましたが、それとも違うと言います。なぜなら、ツイッターではコンテキストが違う人が集まって、思い思いにつぶやいているため、共感しにくいし、面白さを感じにくいからだと指摘しました。
しかしマストドンでは、インスタンスごとに分かれたローカルタイムラインには、そのインスタンスの特徴にそった人たちが集まるせいか、ローカルタイムラインに一体感があり、そこを眺めているだけでも楽しいとし、この点が今までと違うと話しました。
また、マストドンではログインした瞬間に、そのインスタンス内のコミュニケーションが見えて、しかもすぐに参加できます。フォローしなくても発言すれば誰かに見てもらえます。そこがツイッターとは違う面白さがあると述べました。
現在インスタンスがあちこちで立ち上がっていますが、Pawooやmstdn.jpなどの大規模のインスタンスを見て、よりたくさんの人が集まっている街、さらに言えば歩行者天国でのパフォーマンスを見ているように、清水さんは感じたそうです。ローカルタイムラインを見ているだけでも楽しめるし、自分がパフォーマンスを行えば楽しんでもらえると語っていました。そのことを通して、自分が興味を持つコンテンツやユーザーを見つけられるし、見つけられやすさが、ローカルタイムラインという場所から感じられたと言います。
清水さんは、もともとコミュニケーションのサービスをやっていくうえで、こういうことをしてみたいと思っていたと明かします。新宿、原宿、渋谷、秋葉原などの若者文化が場所と人によって生まれてきましたが、秋葉原の次の若者文化はウェブに移動したのではないかと言います。例えば、ウェブ上にはいろいろな場所がすでに存在していて、ツイッターやFacebook、YouTube、ニコニコ動画、pixivなどで文化は生まれています。
しかし、それぞれ扱っているコンテンツやその形式が違います。そこで、もう少し統一された規格上にある、ただの場所に集まる人よって、文化が生まれるようになると思っていたそうです。マストドンと出会って、それが新しい文化が生まれるプラットフォームになると感じた清水さんは、瞬時にやるしかないと思って、Pawooをほとんど勢いで始めたそうです。それに対して会社が共感してくれ、かなり力を入れてくれていると述べていました。
なぜpixivがインスタンスを立てるのか、そしてPawooのこれまでとこれから
pixivは創作活動を支えることを経営理念としています。創作活動を支えられるのであれば何をしてもいいという社風です。これまでもいろいろな周辺サービスを作ってきましたが、制作を支えることが中心でした。しかしながら、活動の場も支えていきたいと考えていたそうです。その答えにPawooがなりえるのではないかと考え、pixivとして運営することになったと、清水さんは話しました。
Pawooは14日に公開して、現在2週間弱で9万人のユーザーが登録しています(イベント開催時)。
(編注:27日、Pawooの登録ユーザー数が10万人を突破したとのこと!)
清水さんは、Pawooで、これまでどういった機能をリリースしてきたか、これからどういった機能をリリースしていきたいかを次のように説明しました。
- これまでのPawoo
-
- pixivアカウント連携。またPawooプロフィールの画面には、pixivのページに飛ぶバッジを実装(絵描きユーザーの証明に)
- 25日、メディアタイムラインを実装。ローカルタイムラインに流れていく画像のみを流すタイムライン(絵描きユーザーが多い、Pawooと相性が良い)
- 25日、Android版アプリをリリース(他のインスタンスでも使用できる)
- イベント直前に、バージョン1.2.2に更新
- これからのPawoo
-
- ゴールデンウィークあたりでiOS版のリリース(本日リリースされました)
- pixivとの連携強化(pixivの作品を簡単にPawoo上で共有できるように)
- pixivのプロフィールページからPawooへのページへ簡単に飛べるように)
- 画像の扱いの改善(メディアタイムラインをリリースしたが、例えばPawooプロフィールページでメディアだけに絞って表示できるように)
- 複数インスタンス(時期未定。どう分けるのが良いのか、などを検討しているとのこと)
Pawooについて「引き続き、絵描きユーザーに特化した機能を追加いくつもりです」と述べていました。また、「創作活動を支えていく点では、絵描きユーザーに対する活動の場を提供することはできつつあるが、それ以外にも創作のカテゴリがある。そういったカテゴリの活動も支えられるようにしたい」と話していました。
複数インスタンスに対する複数アカウントの問題
最後に、複数アカウントの問題を取り上げました。現在、複数インスタンスに参加するには、インスタンスそれぞれにメールアドレスとパスワードを登録してサインアップする必要があります。しかしそれは面倒です。
清水さんは、マストドンが流行ると、いろいろなインスタンスが生まれ、複数のインスタンスに所属することは当然ありえることだとし、もっと簡単にサインアップができれば良いと考えているそうです。
pixivでは最初、1つのアカウント(以下、共通アカウント)で複数インスタンスに参加できるものがあると良いと考えていたそうですが、今は違うと結論付けようとしていると語りました。共通アカウントは脱中央集権という考え方からしても違うし、分人主義(人格=アカウントを使い分ける)という考え方も実際あるはずだと、清水さんは指摘しました。例えば、ツイッターやpixivもそうですが、アカウントは複数持っている人はたくさんいます。これは、コミュニケーションする相手によって人格を変えたいからだと言います。
それを踏まえて、インスタンスそれぞれの文化が違う場所に所属するときに、結果的に共通アカウントは使いにくいものになるのではないか?と考えているそうです。また、インスタンスごとに人格を持つほうがマストドン的に良いのではないか、ユーザーとしても自由にその場その場で楽しめるのではないか、と話しました。
そこでPawooでは、脱中央集権的ではないけれども、pixivアカウントなどで簡単に各インスタンスのアカウントを管理することを考えているそうです。インスタンスへのサインアップのハードルが下がれば、複数のインスタンスに入ってコミュニケーションができるようになるはずだと述べていました。
「実運用してみてわかった、大規模Mastodonインスタンスを運用するコツ」
道井さん(@harukasan@pawoo.net)は、inside.pixiv.blogに書いた「実際に運用してみてわかった、大規模Mastodonインスタンスを運用するコツ」について話しました。

最初に、PawooのソースコードはGitHubにあるので参照してほしいと言及しました。
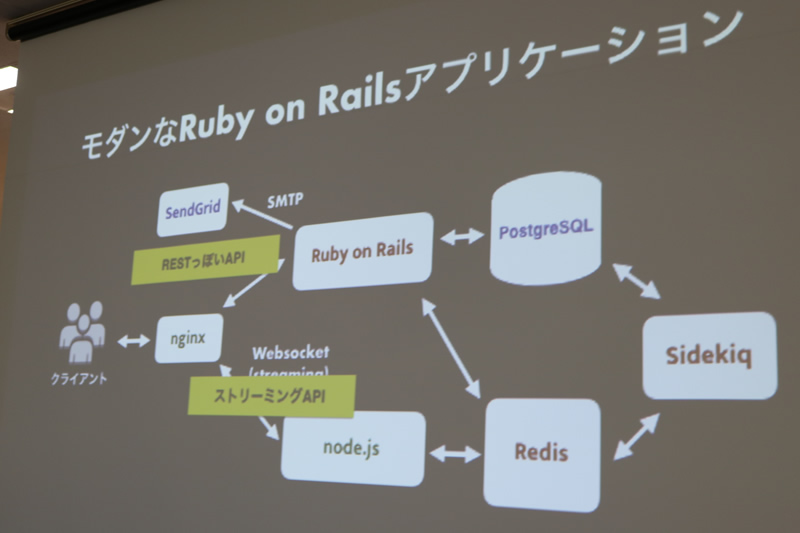
マストドン・Pawooの構成
マストドンはPostgreSQL、Redis、node.jsなどを使った普通のモダンなRuby on Railsアプリケーション構成で、nginxがまとめて通信します。
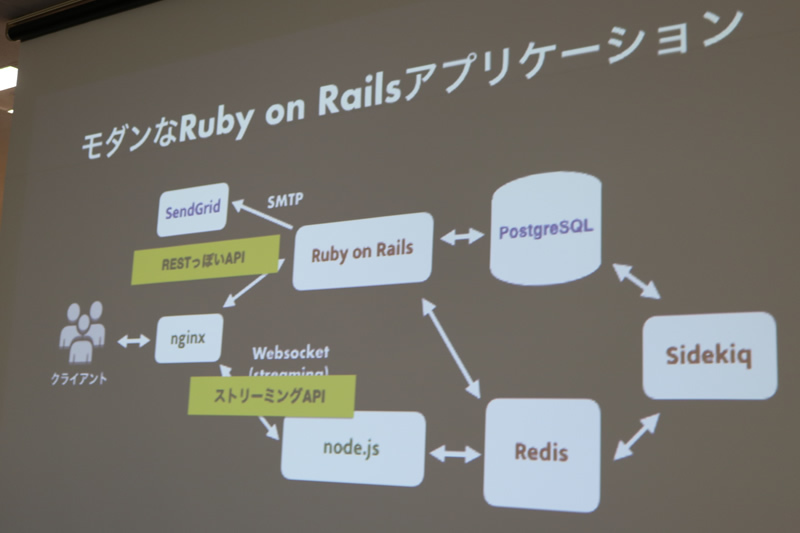
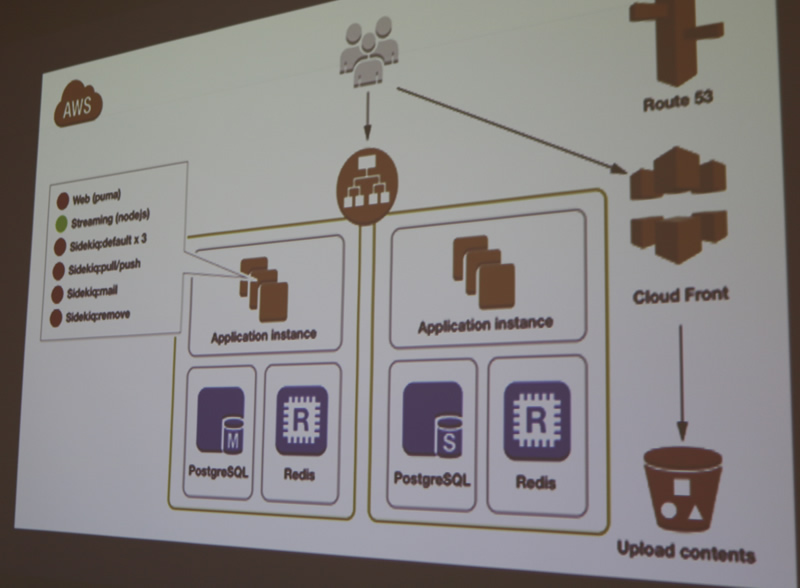
PawooはAWSに載っています。リリースまで時間がないけど一番優先されるのは安定性という、かけ離れた要求がされたと、道井さんは振り返っていました。
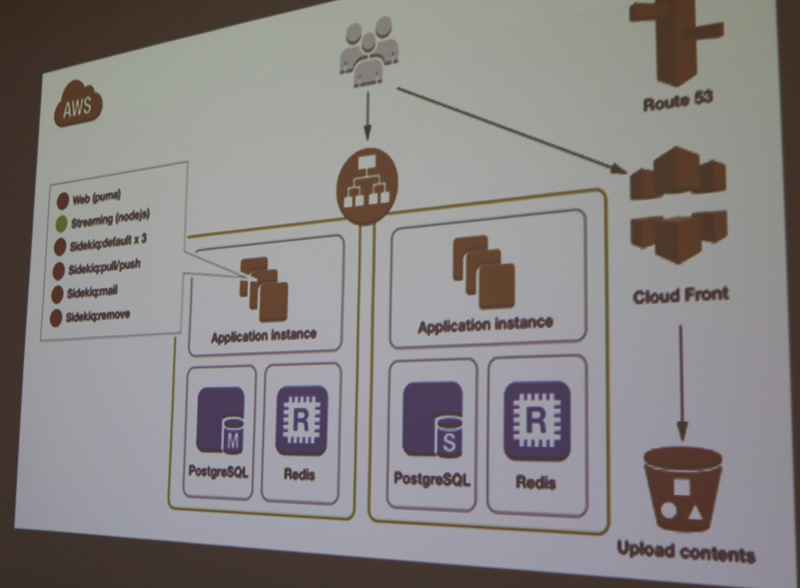
マストドンのようなサービスを自社のオンプレで動かすノウハウは持っているけれども、さすがにオンプレのサーバーで安定したものを作るには時間がかかると言います。1か月程度の期間限定サイトを作るときにはAWSを使うことがあるので、今回はそのノウハウを使って進めたそうです。RDS/ElasticaseのマルチAZ構成、メディアはS3に保存、EC2を並べてALBでロードバランスする形でで作ったとのことです(図のCloud Frontは使っていないとのこと)。
基本的にはEC2インスタンスを並べています。すべてのEC2インスタンスは同じ構成で、AMIでシュッと増やしていると説明しました。ただし、オートスケーリングが全く考えられていないため、そのうちオートスケーリングするか、 スポットフリートに載せることを検討しているそうです。
なお、マストドンはDockerを使っていますが、Pawooでは全部はがして各サービスをsystemdで管理していると補足していました。Dockerのまま使っても良いのですが、Dockerを使うことで、そのために検討・対応する時間が増えることを回避したかったそうです(DockerのままだとECS使えて便利なのですが、ECSだとホットデプロイを考えたり、リソースをうまいことをやったりとか、そのあたりを考えないといけないとのこと)。
エラーの改善
実はここまでの作業は、道井さんは携わっておらず、新人さんらが行ったことだったと言います。その日のうちにPawooがリリースされましたが、すぐにエラーが出始めて、翌朝にnginxのエラーログから見始めたそうです。nginxのエラーは、設定を変更して直したとのこと(バランシング自体はEC2のnginxではなくALBを使っているそうです。『nginx実践入門』を読めば分かると薦めていました)。
また、マストドンはPostgreSQLを使っています。pixivではほぼMySQLを使っているため、知見があまりないそうです。PostgreSQLの場合は、コネクションを張るごとにforkします。そのためマストドンでは、コネクションを張り過ぎるとCPUをとても喰うことにつながります。そこで、Railsのコネクションプールの数を上手い具合に設定して、良い感じになるよう調整したとのこと。あとはEC2インスタンスをスケールアップして対応しているそうです(可用性とバックアップはRDSにお任せとのこと)。つまりお金で解決しているため、知見を求めていると話していました。なお、コネクションプールについては、PgBouncerを使うことも検討しているとのことですが、怖くてまだ使ってないと述べていました。
メインロジックはSidekiq
マストドンのメインロジックは、ジョブ中のしくみを記述しているSidekiqのほうにあると言います。マストドンではSidekiqをメッセージパッシングに使っています。つまりstreamingなどをジョブとしてSidekiqに登録しています。
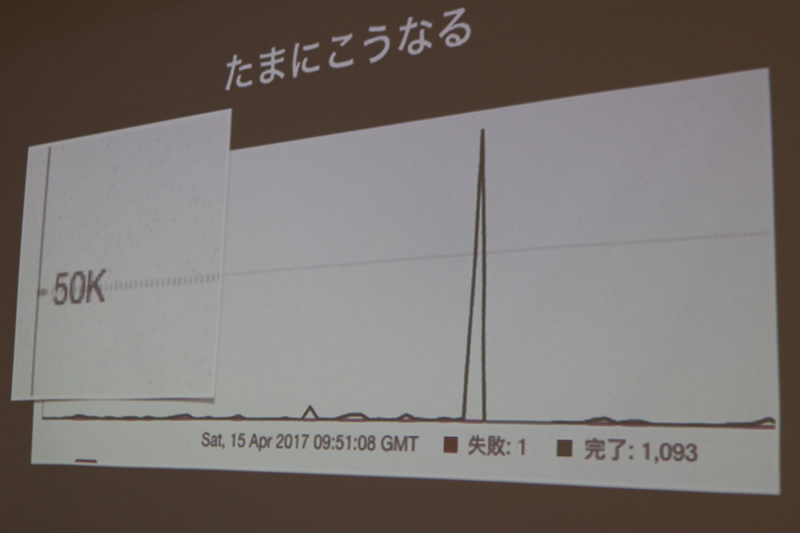
例えば、1トゥートされると、フォロワーの数だけSidekiqに変身します。これは相当やばいと言及していました。フォロワーの数が多いと、その分かさむからです。
普段からダッシュボードを見ると、2秒で1,000とか2,000とか処理しているのが分かりました。次の図のように、たまに50,000という数値が出たりしているそうです。道井さんは「普段は見ることができないSidekiqの様子を見れるのがマストドンだ」と説明しました。
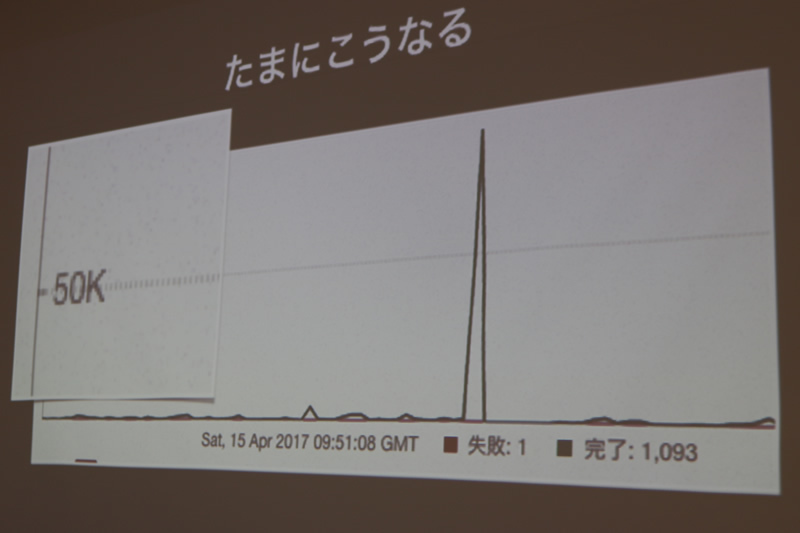
マストドンのキューの種類はpull, push, mail, defaultです。本当はキューを分けたほうが良いのですが、そういうissueを立てたら、これでもせいいっぱいだ、と言われたので、これからもこの数だろうと話していました。
一番の問題は、Sidekiqが詰まることです。デフォルトだと、すべてのキューが1つのSidekiqプロセスで処理することになっています。このうちのpullとpushがリモートインスタンスに対してメッセージの配信を行いますが、例えばリモートインスタンスのpullとpushのキューが詰まると、pullとpushが詰まり始めることになります。そうするとSidekiqのキューが増えていって、結果タイムラインが遅延してしまいます。
つまり、Pawoo自体を改善しても遅延してしまい、サービスが続けられないことになります。そこで、Sidekiqのプロセスを分ける必要があると言います。また、Sidekiqは1プロセスで1コアまでしか使ってくれません。そのため、プロセスをたくさん立ててカバーする必要があります。
よって、実際には1インスタンスだけで、1,000スレッド以上のSidekiqが動く代物になっていると言います。こうすると、Sidekiqのプロセス画面がだいぶ見づらいし、とても重いのが課題になっていると述べていました。

課題としてはさらに、リモートインスタンスが詰まるのが解決しないことです。例えば大規模なmstdn.jpが詰まると、ほかのインスタンスにも配信されなくなります。そこで、がんばってプロセスを立てるのですが、プロセスを立てるとその分だけリモートインスタンスに配信することになり、DoSのようになってしまうと説明しました。つまり、お金の力で増やしまくっても良くないという問題です。つまり、遅いインスタンスや大規模インスタンスの処理をどうにかしなければいけません。道井さんは「そもそもトゥートあたりのジョブ数がN+1になっているのがやばい」と述べていました。
最後に、道井さんは「マストドンのメインはRailsではなくSidekiq。そのジョブをうまく捌けると良い。将来的にはsidekiqプロセスをスポットインスタンスで並べるのが良いと思っているが、その前に最適化されると良い」と話しました。また、「僕らは立てて2週間経ってないので、そもそも最適化というとこまでいきつけてない。とりあえず今は捌くことを考えて作業しているが、そもそもうまく行ってないので、ここは変わるはずだ」とも述べていました。
「なんかnodeのCPU使用率が100%で張り付いててマジヤバかったのでなんとかした話」
片倉さん(@geta6@pawoo.net)の発表は、Pawooリリース日の23時頃、マシンは大丈夫だけどnodeのプロセスのみ使用率100%で張りついてるという話を受け、それを改善した話でした。

マストドンでは、WebSocketを使ったstreaming関連のAPI実装が1ファイルでできていて、つまりポエムで書かれていると言います。PostgreSQLのコネクションプール、Redisコネクション、HTTPインターフェース、WebSocketインターフェースが全部1つのファイルになっているそうです。
また、npm scriptを見ると、この実装がbable-nodeコマンドを使ってES2015コードを直接起動する筋力運用になっていると説明しました。特にpm2などのマネージャーは挟んでいなくて、普通にnodeを起動しています。
node.jsはシングルスレッドであるため、コア数の違いでパフォーマンスは変わりません。元のコードは素直な実装で、1サーバーあたり1プロセス、つまり1コア分しか利用できない状態でしか立てられないものでした。つまりCPU負荷が偏った状態になります。このため、マストドンを動かしているサーバーとしては大丈夫なのに、nodeのプロセスだけが100%で張り付いて、マストドンのページは普通に見えるのに、なぜかストリーミングが流れないとか、タイムラインがとても遅れる状態になっていたと説明しました。
この解決には、nodeのプロセス数を増やしスケジューリングして、サーバー内のコア間で負荷を分散する方法が一般的です。定石としてはpm2などのプロセスマネージャーを使って、いい感じにnodeのプロセス数を増やします。そうすると一個一個プロセスを殺させることで、サーバーが耐えられるようになるそうです。
そこで、片倉さんはpm2のconfig fileを書いて動かしてもらったのですが、systemdとpm2の相性が悪いのか、片倉さんの書き方が悪いのか、動かなかったそうです。しかしリリース後で、ユーザーが困っているため、早く解決しないといけません。ここに至り、もっとも手っ取り早くnodeをマルチコアに対応させる、clusterモジュールを使って解決しました。
clusterモジュールは、nodeに標準でバンドルされていて、クラスタリング機能を持った、だいたいのプロセスマネージャーの基礎になっています。導入は簡単で、次のようなコードで書けます。(コア数 - 1)しているのは、forkしたプロセスが爆発した時にサーバーが吹っ飛ばないようにするためだと説明しました。

結果、マルチコアを全部使いきれるようになりました。なお、fork元がmaster、fork先がworkerとプロセス的には呼んでいますが、workerへの仕事の割り振りはOSが勝手にしてくれます(設定すれば、ラウンドロビンも選択できるとのこと)。
ここまでの話は、バージョン1.2.2で本家に取り込まれています。片倉さんは「ぜひ試してみてください」と話していました(“Very interesting!”と言われて承認欲求がえられるとのこと)。
クラスタの話は以上ですが、次の2つの改善にも触れていました。
- タイムライン一番下までスクロールした時に無限にXHRリクエストが走るのを抑制した。たぶん実装忘れで、ReduxのAction/Reducerにnext-urlが存在しないときの処理を入れた。
- トゥートとするときのテキストエリアのサイズを自動的に変更するようにした。難しい印象を持たれるが2行でできる。

休憩
ここで休憩になりました。参加者には、ピザとアルコールが振舞われました。

「アプリを最速でリリースした話」
三津山さん(@chocomelon@pawoo.net)の発表は、リリースしたばかりのAndroid版Pawooのアプリ開発の模様を紹介しました。発表の冒頭では、アップデートのリリース作業を行ってから話が始まりました。

Androidアプリはネイティブ
Androidアプリ自体は、きちんとネイティブで作ったと言います。構成は、MVPっぽいアーキテクチャで、Retrofit、RxAndroid、Data Bindingとかを使っているそうです。ただ、そんなことはどうでも良くて、とにかくスピード重視で作ったと話しました。なお、対応バージョンは、pixivのアプリは4.0.3を切ったばかりですが、このアプリは5からであることを補足していました。
このアプリは基本的に全部のことをできることを意識して作っているそうです。それは、競合クライアントの中でPawooのアプリを使ってもらうとなると、メイン機能を絞るのは難しいと考えたためです。その結果、実装に全力を出すことになったと述べていました。
アプリ開発の進行の模様
アプリはほぼ6日で作ったとし、三津山さんはその模様を振り返りました。
1日目は、自分一人だけで開発していました。午前中に話があり、ログインから作って、ホームタイムラインを表示するように進めたそうです。
しかし2日目になって、1週間程度で作るのは厳しいと思い始めたとのこと。ただ人を入れるにしても、同時並行にするのはこのままでは結構難しく、人を受け入れられる体制を作ろうとしたのが2日目だったと言います。ハンバーガーメニュー・タブメニューを作ったり、タイムラインの構造はだいたい一緒であるため、ベースの構造をしっかり作ったりしたりして、人が増えたときに単体でページが作れるように、作業を進めたそうです。
2日目終わった段階で、以下の図のように、ログインがWebViewからできて、タイムラインを取ってこれるものができていました。
3日目に一人増やしました。そして、インスタンスがPawoo限定になっていたので、他のインスタンスでもログインできるようになりました。また、自分たちが使っていて楽しいと思う機能を最初に実現したかったので、アクション回りを作っていったそうです。社内に中途半端な状態でも配布して使ってもらい、フィードバックを受け取れるようにするため、DeployGateの整備もしたそうです。
4日目からは4人体制になりました。プッシュ通知や、細かなブラッシュアップを行いました。結果、4日目には、タイムラインがきれいに見えるようになり、ユーザーページも見れて、アクションもできて、一通り雑にはそろったと言います。
5日目は、アプリのメインの体験とは違うところを作業を行いました。通知・Fav一覧、翻訳リソース、画像付きトゥートなどです。6日目はバグ修正、つまりブラッシュアップの時間となりました。そのほか、プレスリリースの準備を行いました。
最終的にリリースされて
pixivのアプリでも、Androidだけで4名体制は相当リソースを割いていたことになるそうです。三津山さんは「ハッカソン的なノリで一気に作った」と言います。適切な時に適切な人数・人材を投入したのが良かったとし、多少バグは残ったりとか、足りない機能みたいなのはあったが、それなりに使ってもらえるクオリティにはなったと話していました。
また、全員がマストドンのことを理解していたため、アプリとしてどうすべきか、楽しめるかなどのフィードバックがきちんと出たことが、ブラッシュアップにつながったと述べていました。
ただ、正直6日もハッカソンのノリで作業するのは相当きつく、最後のほうは消耗していたとも述べていました。
これからは、複数インスタンスへの対応やアカウント検索、Pawoo独自の機能への追従、フィードバックへの対応をしていくそうです。Pawooが使いやすく、ほかのインスタンスでも使えることが、結果、Pawooの認知やこのアプリを使ってもらうことにつながるはずだと話していました。
「Mastodonを3倍速くしたい話」
石井さん(@alpaca_tc@pawoo.net)は、マストドンのスピード改善について発表しました。

石井さんは、もともとPawooの開発に関わっていませんでしたが、エラーが出ているという開発陣の会話を見て、その修正点を指摘した流れで、そのままPawooの開発に携わるようになったそうです。
Pawooのサーバー構成
現在のマストドンはとても重く、現在(イベント時)のPawooは次の構成で動かしていると言います。
- APサーバー10台
- Sidekiq、60プロセス、1,400ワーカー
- DB40コア、メモリ160GB(イベント時にはDB16コア、メモリ64GBに改善)
現在、最適化を進めていて、現在できたことと、これから行いたいことを話しました。
DB最適化
マストドンのデフォルトでは、アドミンだけが入れる/pgheroにアナライザなどが入っています。これでDBのクエリを見ることができます。それをずっと眺めていると「これなんか遅いな」というのが、まだまだあると石井さんは言います。つまり、DBに最適化の余地がありました。
例えば、遅いクエリのためにindexを張ったことを取り上げました。これにより、DB40コア、メモリ160GBから、DB16コア、メモリ64GBになったと言います。(グラフは機能追加で障害が入った直後の個所なので結構見づらいとのこと)。

実際コードを見ていると、まだまだindexが張れていなかったり、クエリが遅い箇所があるので直していきたいと述べていました。
リモートインスタンスへのリクエストを改善
マストドンはリモートインスタンスとの通信が必要です。そのデフォルトのタイムアウトは長いもので60秒もありました。そのままの設定だと、弱いインスタンスでは即詰まります。そこで、Goldfinger、PubSubHubbub、AtomServcieなどのタイムアウトを短くするのが良いと話しました。

そもそもタイムアウトやリモートインスタンスを改善するには、マストドン自体を改善するしかありません。そこでpixivでは、Pawooを最適化して、本家のマストドンにプルリクエストで貢献しています。実際、次のバージョンはこの貢献によって速くなるし、これ以降も貢献していくことで、リモートインスタンスもPawooも速くなって、みんな幸せになることを目指していると述べていました。
mstdn.jp DoS攻撃の改善
リモートインスタンスがメンテナンスに入ると、例えばmstdn.jpが落ちると一気に数万件のキューが、どかんと溜まると言います。この解決のために、賢いretry戦略を検討しているそうです。それは、リモートインスタンスが落ちていることを把握することで、接続可能なリモートインスタンスのジョブが詰まることを避けることだと話します。
失敗したリクエストなどをホストごとに管理することを考えているとし、例えばRedisに集計して、10分以内にリクエストが失敗したら、そこへのインスタンスは何十分間遅らせることなどを検討しているそうです。
Sidekiq N+1問題の改善
道井さんのセッションでも取り上げられましたが、ユーザーがつぶやくたびに全フォロワーに通知が飛びます。
実際に、次のようなコードになっていて、workerを積んでいく形になっています。

Sidekiqに積まれるのは、Redisに積むためにIDの数値のみになっています。オブジェクト自体は積まれません。そうすると、実質N+1になります。SidekiqにはIDしか積んでないので、ジョブのなかで引き直す必要が出てきます。
これに対して石井さんは、where(id:ids)で一気に全件を取ってきて処理すればDBへの負荷が減るはずだと考えていて、次のようなperform_async_in_batchesといった仕組みを導入することを検討しているそうです。

これによって、バッチサイズを設定することができ、また1を指定しておけば現在のマストドンの挙動と同じになります。もし500とか1,000とかのバッチサイズを設定できれば、それをまとめて処理することで、N+1問題を改善したいと話していました。
最後に、石井さんは「pixivではすでに30近くのPRを本家のマストドンに送っています。これからもマストドンをどんどん引っ張っていきたいです。ぜひ興味がある人は来てください」と締めくくっていました。
すべての発表後に懇親会が催されました。随所でマストドンの感触や運用ノウハウなどが語られていたようです。そのようななか、片隅でPawooチームが開発している風景も見られ、マストドン・Pawooの勢いが感じられるイベントとなりました。