



「実践的データ基盤への処方箋」
- データエンジニア大集合!
「実践的データ基盤への処方箋」 輪読会レポート 〜データ整備編〜 (今回) - データエンジニア大集合!
「実践的データ基盤への処方箋」 輪読会レポート ~データ基盤システム編~ (第2回) - データエンジニア大集合!
「実践的データ基盤への処方箋」 輪読会レポート 〜データ組織編〜 (第3回)
データエンジニアリング、
データ基盤に応用されるソフトウェア開発のノウハウ
第1回の輪読会では、
株式会社ナウキャストの隅田 敦氏が1人目の発表者を務めました。隅田氏が担当したのは、

隅田敦(@yummydum)
自己紹介: 東京大学経済学部経済学科にて計量経済学を専攻。経済現象の理解のためには高品質高頻度のデータが必要との想いから2018年よりナウキャストにてインターンを始める。2019年より東京大学大学院情報理工学系研究科コンピュータサイエンス専攻に進学し、
現在は、
- 第1章 データ活用のためのデータ整備
- 1-1 データの一連の流れを把握し、
入口から出口までを書き出す - 1-2 データの品質は生成元のデータソースで担保する
- 1-3 データが生じる現場を把握して業務改善につなげる
- 1-4 データソースの整備ではマスタ・
共通ID・ 履歴の3つを担保する
1章の内容については、
- 隅田
- 「著者のゆずたそ氏は、
CRUD表 (データのC:Create、 R:Read、 U:Update、 D:Deleteをまとめた表) を作成して、 データを洗い出すことを提唱しています。例えば、 販売促進部が雨天限定でメルマガ (クーポン) を発行したいというユースケースがあったときに、 どういうデータが必要になるかを考えます。雨が降っているか否かをデータから判断する必要があるため、 気象庁のデータが必要と判断したとします。この場合、 天候というデータに対して気象庁が行うCRUDはCreateとUpdateで、 メルマガシステム開発部のメルマガの部署がそれをReadします。」

隅田氏は社内でもCRUD表を使ってみたいと話します。続いて、
- 隅田
- 「業務レイヤという考えが提唱されています。業務レイヤをもとにデータを整理すると、
データマネジメントにおける課題の原因や改善案が考えやすくなります。」

- 隅田
- 「ある作業を、
ロールとオペレーションとアプリケーションとストレージという観点で整理します。ロールは作業を行う人、 あるいは自動化されている場合はシステムです。オペレーションは、 作業を完了するためのアクションです。アプリケーションは、 そのアクションに用いる道具です。ストレージが、 データ保存する物理的な場所です。 - 例えば、
営業活動を毎日モニタリングしたいとします。営業活動の中で、 営業スタッフが商談のメモを紙媒体に入力するという状況があったとします。アプリケーションの観点から見ると、 紙媒体へのメモではなく、 入力システムを導入したらどうかという改善案が考えられます。この場合、 紙で書くよりも手間がかかるので商談時間が減るとか、 システムを導入すると利用料がかかるという欠点も考慮する必要があります。 - 次にロールに注目して、
営業アシスタントに入力してもらうという施策も考えられます。 この場合、 業務も安定するし商談時間も減らないというメリットがある一方で、 人件費やアシスタントの教育にコストがかかるというデメリットもあります。あるいは、 オペレーションに注目して、 OCRで紙のメモを自動でデータ化するという方向性も考えられます。この場合, 紙というアプリケーションは変えなくていいので楽ですが、 OCRの品質が問題になります。」
業務レイヤごとにPros/
- 隅田
- 「全社的にデータ活用したいとなったときに、
よく問題になる3つのデータということで、 マスタ、 共通ID、 履歴が挙げられています。」

システムや部署によって、

- 隅田
- 「本書は、
ソフトウェア開発において重要なノウハウが、 データ基盤の分脈に応用されています。ユースケースやユーザーストーリーを明確にすることはデータ基盤に限らず重要で、 データ基盤の三層構造も責務が明確なサブシステムで分割しようという、 一般的なソフトウェア開発の原則にのっとっています。 - また、
ドメインを深く理解することが重要というのは、 例えば売上という概念をとっても、 経理部門から見たときの売上とECサイト側から見たときの売上はまったく定義が違うので、 データ分析以外の観点でも問題になりそうです。ドメインごとに用語の定義をして、 関係者の理解をそろえることはデータ分析に限らず重要です。」
発表後には、
- 山田
- 「部署ごとに報告する売上が違って社長がブチ切れた
(笑)。私が過去に見た例では、 ROIを取り合うこともありましたね。」
発表者の隅田氏が著者のゆずたそ氏に質問を投げかけました。
- 隅田
- 「業務レイヤという考えに至った経緯は何でしょうか?」
- ゆず
- 「エンタープライズアーキテクチャ
(EA) という、 日々の仕事をどうやって改善していくのかを整理するような知識体系があります。DMBOKの中でも紹介されています。EAでは、 さまざまな仕事をレイヤに分けて整理します。EAを参考にしつつ、 データを扱う場合の重要な点をふまえて整理し直したのが業務レイヤという考え方です。」
参加者からの
- 山田
- 「トップダウンで決めるのが良いですね。ボトムアップでやろうとすると、
ガバナンスが効かず、 本人に任せるような状態になってしまいます。」
これに加えてCDOなど設置する企業は見本のようなもので実際にはIT部門に丸投げになってしまう現状があるなどのコメントも寄せられました。

山田雄(@nii_yan )
SIer にて組込系の開発に従事したのち、データ整備の課題はテクノロジーだけで解決できるのか?
2人目の発表者のしんゆう氏は

しんゆう(@data_analyst_ )
知ることに強い興味があり、
- 第1章 データ活用のためのデータ整備
- 1-5 データレイク層の一箇所にデータのソースのコピーを集約する
- 1-6 データウェアハウス層では分析用DBを使って共通指標を管理する
- 1-7 共通指標は本当に必要とされるものを用意する
- 1-8 特定用途に利用するデータマートはユースケースを想定してつくる
データレイク層とはデータを集約したもので、
- しんゆう
- 「データレイクがデータレイクになっていないという問題が挙げられています。分析用に集計してから連携してしまう。複数の箇所にデータレイクをつくってしまうなどです。ほかにも、
データレイクが存在してもそこにアクセスする権限がないことや、 データレイクにデータがあるのかどうかわからないなどの課題があると思います。」

データレイクを1箇所にデータを集める理由として、
- しんゆう
- 「部署ごとに独自の集計をしてしまうと、
部署横断のデータ活用が進みません。SSOT (Single Source of Trust:信頼できる唯一の情報源) として、 一箇所で定めておくことが必要です。少なくとも同じデータを使っていれば、 売上を集計するときに定義がぶれなくなります。 - 部署が違えばルールも変わるので、
売上が違うという話になれば、 間違い探しが発生してしまいます。共通指標は集計があった方が良いこと、 これはガバナンスにも関係すると言っています。」

共通指標は複数のデータを統合・
次に、
- しんゆう
- 「1つは影響範囲を制限できること、
もう一つは集計ロジックを再利用できることです。データ利用の視点に立つと、 試行錯誤が容易になること、 過去のロジックを再利用できること、 システムの応答時間が速くなることがメリットだと言っています。」
さらにしんゆう氏はデータマートについての自論を展開します。
- しんゆう
- 「大きなテーブルにクエリを投げても、
システムの応答時間が気にならない程度にツールが発展すれば、 ユースケースごとにクエリを持つだけで、 データマートという入れ物はなくなるのかもしれないと思います。」
続いて、

しんゆう氏はデータマート層の課題とその解決法について、
- しんゆう
- 「本書では、
ツールが利用者との間で分断されるのを避けるには、 最初の試行錯誤はBIや表計算ソフトで行って、 利用方法が固まってきたらSQLに書き直すことを推奨しています。データマート自体が増えすぎる問題は確かにありますが、 定期的に見続ける予定がなければ、 アドホックなクエリだけを残しておく方法もあります。また、 データマートやクエリを作っても、 ある期間を設定して消えるようにしておく方法もあります。」
最後に以下のように発表をまとめました。
- しんゆう
- 「主にテクノロジーで解決するための方法が書かれている印象を受けました。データ整備は対人スキルが必要になるケースが少なからずあって、
そこを埋めてくれるコンテンツに需要がありそうだと思います。」
しんゆう氏は、
- ゆずたそ
- 「たとえば、
ある会社では四層で作っているという話を聞きました。非構造データをテーブル形式に整えるとか、 列名をわかりやすく変換するとか、 元のデータのセマンティクスを変えない範囲内での変換を行っているようです。 - 本書の流れでは、
ユースケースとデータソースという文脈があるので、 そこに注目してください。ユースケースに紐づく層とデータソースに紐づく層、 そしてその間を横断する層があります。この二層目は、 粒度によって複数の層があり得ると思います。例えば、 ソースコードを書くときに、 エンジニアがクラスとパッケージとコンテキストをどう区別するかのような話と同じです。コンテキストという粒度なら三層かもしれないし、 クラスまで分けるならもっと増えるかもしれません。そこは設計次第だと思います。 - 重要なのは最初のコンテキストの切り方は、
データソースとユースケース、 データの入口と出口に注目しましょう。それ以外にもう1つ必要になるはずというのがこの三つの分け方です。」
データスチュワードは存在するか?
最後の発表者はmomota氏

momota(@momota10s)
大学を卒業後、
LinkedIn: https://
- 第1章 データ活用のためのデータ整備
- 1-9 ユースケースを優先的に検討しツールの整備を逆算する
- 1-10 データの調査コストを減らすためにメタデータを活用する
- 1-11 サービスレベルを設定・
計測して改善サイクルにつなげる - 1-12 データ基盤の品質を支えるデータスチュワードの役割を設ける
そもそもデータ基盤を作るのは、
- momota
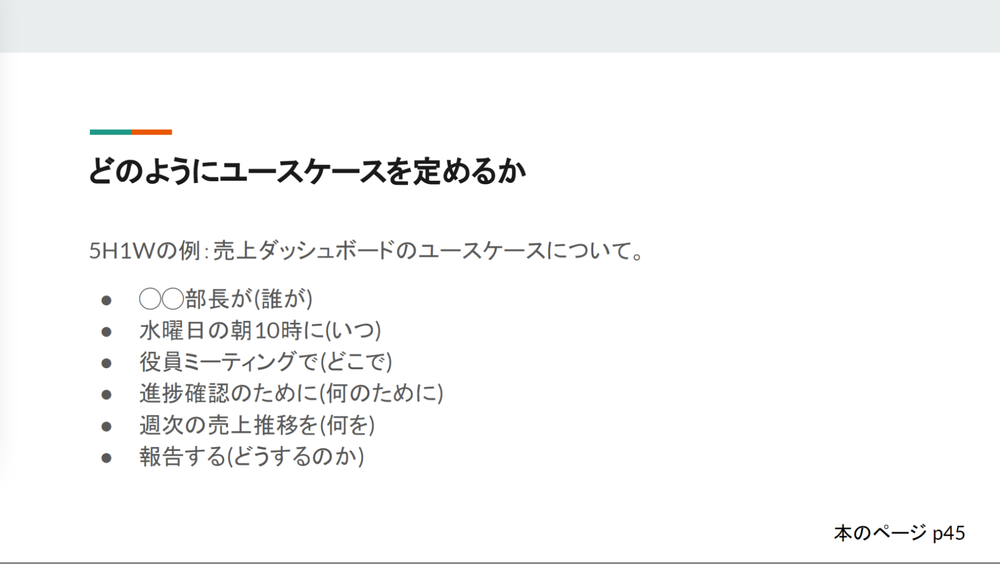
- 「事業計画の目標を達成するために、
施策から逆算してユースケースを定める。施策の解像度の高さが良質なアウトプットへの道しるべだと書いてあります。5W1H (画像は5H1W) の例では、 誰が、 いつ、 どこで、 なんのために、 何を、 どうするのか、 まで解像度を高く設定してあげることで、 実際にユースケースを満たすためのデータ基盤、 またその先のBIツールなど、 確度高く仕事が進められると書いていて、 その通りだなと思います。」
事業目標にそぐわない課題、
- momota
- 「どのようなデータなのかを知るために付与される情報です。写真データで言うと、
いつ撮影されて、 拡張子、 撮影場所といった付随する情報などをメタデータと言います。データ基盤におけるメタデータは、 データの作成者、 作成日時、 カラムに個人情報が含まれているか、 単位、 参照数など、 たくさんあります。私自身、 BigQueryをよく使うので、 パブリックデータの例をお見せします。」
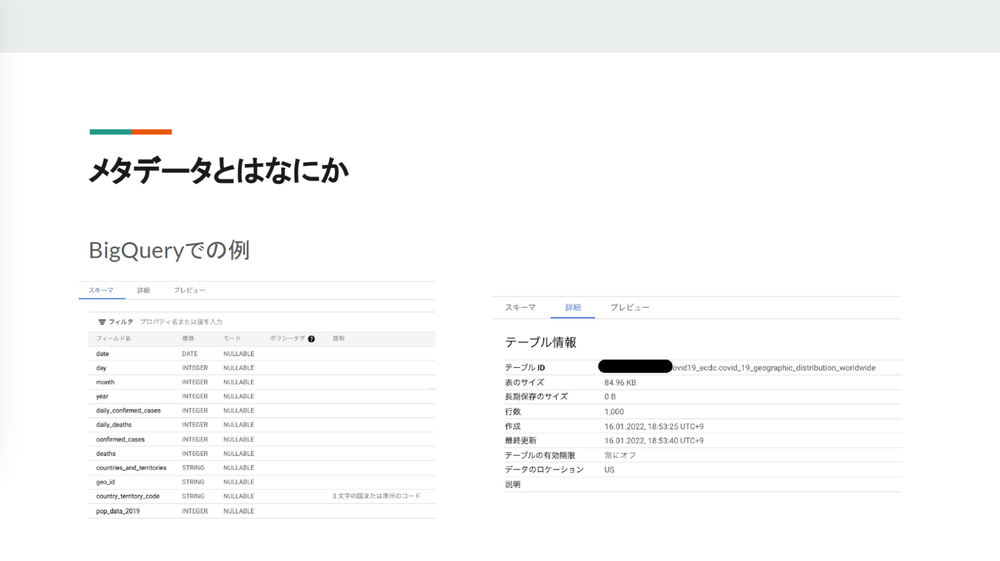
- momota
- 「フィールド名に対して説明をつけたらそれがメタデータになりますし、
そもそもテーブルのIDやサイズなどの情報もメタデータです。」
なぜメタデータを管理すべきなのかについては、
- momota
- 「とあるECサイトの注文のレコードに、
「payment_ type1、 2、 3」 という整数があって、 「1、 2、 3」 が何なのか、 ソースコードを調べるか、 知ってる人に尋ねないとわからないことがありました。メタデータが整備されてないと、 調査コストがかかるのはその通りです。メタデータはデータ活用の画面だけではなくて、 データパイプラインの作成過程でも役に立つと書いてあります。」
続けてmomota氏がどのようにメタデータを管理しているかにふれます。
- momota
- 「(メタデータの管理は)
BigQueryやData Catalogで行います。分析用のデータベースやメタデータ管理ツールですね。他のクラウドサービスであっても、 自社サービスであっても、 作成者自身が書きます。とはいえ、 スプレッドシートやExcelで管理されていることも往々にしてありますし、 BigQueryにメタデータ拡充したから見てね、 と言っても誰も見ないこともありえます。ここでも、 ユースケースをよく考えることは重要だと思います。」
このように話したあと、
- momota
- 「サービスレベルとはサービスの品質水準を表現したもので、
データ基盤には簡単にアクセスできる便利さと整備済みデータを使える安心感という暗黙的な期待があります。サービスレベルは、 目標設定から関係者との合意、 計測、 特定、 施策の実施、 振り返りといったサイクルで品質の向上を継続します。なぜサービスレベルを計測するかですが、 計測によって課題が明確になって改善策につながるからです。」
このように解説し、
- momota
- 「可視化が第一です。そのうえで、
ビジネス要件や、 要望がある人へのヒアリングを通して目標設定をしていきます。ここで、 ユースケースごとに期待されるサービスレベルが異なるというのはミソだと思います。経理向けの集計データと分析向けデータは、 求めるデータの品質が全然違います。」
最後にデータスチュワードについての説明に入ります。データスチュワードはデータ整備の推進者であり、
- momota
- 「専門の役職もあれば、
データエンジニアやデータアナリストが事実上兼務していることもありますが、 今までの経験上では後者の方が事実上兼務していることがほとんどかなと思います。」
このようにコメントしたうえで、
- momota
- 「LINEは、
ビジネス周りのノウハウ、 あとはコミュニケーション能力、 分析の能力など、 割と幅広く求められているように見えます。マリオットインターナショナルというホテル会社では、 データエンジニアリングよりのスキル、 経験を求めているように見えます。最後にボストンコンサルティンググループは、 コンサルティングのノウハウ、 顧客との折衝動力、 マーケティング能力といったことを求められているように見えます。」
そのうえで、
- momota
- 「データアナリストに内包されている会社が多いと現時点では思っています。データスチュワードが最初のキャリアというより、
データアナリクスやデータエンジニアリングなどのキャリアを積んで、 書籍では 「事実上は兼任」 と書かれていましたが、 事業の数や規模が増えて、 相談窓口としての業務が兼任では収まらなくなったタイミングで、 専任となるのかなと考えました。」
続いて、
- momota
- 「(受動的な)
データ抽出や集計などの問い合わせについては、 場合によって別チームに転送します。一方、 能動的なデータ整備の推進について、 問い合わせによって何が課題なのかを知るために、 ユースケースを把握しにいって、 そのユースケースを実現するための品質を定義して、 品質水準や利用状況をメタデータで計測することもあります。必要であればデータソースを整えることも必要です。なので、 完全に2つの対応が分断しているというよりは、 データを作りにいくところに関わることもあり得るし、 活用する方に関わることもあり得ます。主軸としてはマネジメントなのかなというふうに思っています。」
最後に現場で生じる課題と対処法について紹介しました。
- momota
- 「受動的な活動で時間を割かれることはよくある話です。セールスや事業開発側から、
こんなデータが欲しい、 あんなデータが欲しいという要望に対応していたら1日が終わってる人を見たことがあります。 - 自分の活動、
自分の時間が何に使われているのかを定量的に管理することや、 データ分析一つとっても依頼者が自らの力で解決できるように研修していくことが重要と書かれています。と言っても、 SQLの研修は本当に大変なので、 場合によってはSQLを使えなくてもデータの抽出や集計ができるBIツールの導入もソリューションとして考えられるかもしれません。 - 事業開発もセールスもみんなSQLを扱えるスタートアップ企業に所属していたこともあります。みんながデータについて知っているから、
ドキュメントを拡充するよりも早く分析をして、 試作の結果を見たいという感じでした。事業規模やそこにいる人の能力などによって変わると思います。」
以上で発表は終わりましたが、
- momota氏
- 「データスチュワードの役割としてSQLの研修が挙げられていましたが、
SQLを教えようとしても挫折する方が多いので、 最終的にはTableauを導入するという話になったこともあります。結局、 SQLの基本的な構文を覚えても、 データモデルを理解していないとまったく立ちゆかないと思います。それを他の職能の人に期待するのは負担が大きいです。組織規模が大きくなって分業化が進むと、 データ基盤を作る人が専任になって、 他は見るだけの人のように分かれるんだろうなと思います。」
最後に著者のゆずたそ氏から、
- ゆずたそ
- 「正解を勉強するために本を読むわけではないと思っています。みなさん自身がよりよい活躍をして、
より世の中を良くしていく仕事をしてるんだと思うんですけど、 本書がそういった仕事を後押しできればと思っています。そういう読み方をしてもらえるとすごくいいかなと思っています。」

ゆずたそ(@yuzutas0)
本名:横山翔。令和元年創業・