


今回はAI文章画像解析エンジンであるYomiTokuを通じて、GPUメーカーごとに用意されているPyTorchのインストール方法を紹介します。
PyTorchとGPU
PyTorchに関しては本連載でも何度となく登場しており、直近だと第877回でした。筆者も文字起こしをする必要がある場合には使用してみたくなりました。
PyTorchと何かというのは、gihyo.
GPUアクセラレーションはGPUのメーカー、もっといえばここではGPGPUフレームワークとしますが、具体的にはCUDAやROCmなどに分けることになります。PyTorchでGPU側の違いを吸収してくれれば、プログラム側では特に考えなくてもよくなることがプログラム開発者のメリットです。理想どおりにいくかどうかはさておきですが。
一方、以前よりOCRに興味があって、本連載でも第577回と第770回で紹介したことがありました。昨今はLLMにOCRをさせるというのも普通に行われており、そのツールとしてYomiTokuを見つけました。OSSではないので必ずしも筆者の好みに合っているわけではありませんが、今回の題材にぴったりなのでここで検証することとしました。
PyTorchのダウンロード
概要
PyTorchのダウンロードは

また、PyTorchのインストール前に第850回を参考に、venvあるいはpyenvあるいはuvなどでPythonの仮想実行環境を作成しておいてください。ここでは特に深い考えがあるわけではありませんがvenvを使用しています。
CUDA編
図1を見てすぐに気づくのは、CUDAのバージョンが12.
ここで思い出すのが、先週のUbuntu Weekly Topicsで取り上げられた
しかし、少なくとも現段階の24.
よって従来どおりの方法でCUDA 12.
$ sudo apt install python3-pip python3.12-venv $ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb $ sudo apt install ./cuda-keyring_1.1-1_all.deb $ sudo apt update $ sudo apt install cuda-toolkit-12-9 $ python3 -m venv ~/yomitoku $ source ~/yomitoku/bin/activate $ pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu129
ROCm編
ROCmは、先日7.
次のコマンドを実行してください。
$ sudo apt install python3-pip python3.12-venv $ wget https://repo.radeon.com/amdgpu-install/6.4.3/ubuntu/noble/amdgpu-install_6.4.60403-1_all.deb $ sudo apt install ./amdgpu-install_6.4.60403-1_all.deb $ sudo apt update $ sudo apt install python3-setuptools python3-wheel $ sudo usermod -a -G render,video $LOGNAME $ sudo apt install -y rocm amdgpu-dkms
再起動後、続けて次のコマンドを実行します。
$ python3 -m venv ~/yomitoku $ source ~/yomitoku/bin/activate $ pip3 install torch torchvision --index-url https://download.pytorch.org/whl/rocm6.4
oneAPI編
IntelのoneAPIでもPyTorchは使えるのですが、このページをよく読むとプログラム側での対応も必要となることがわかります。ソースコードを軽く確認した限りでは、YomiTokuでは対応していませんでした。
YomiTokuを動作させる
最後にYomiTokuを動作させます。まずはインストールからです。Pythonの仮想実行環境下で次のコマンドを実行してください。
$ pip3 install yomitoku
サンプル画像は、第577回で使用したものをそのまま利用することにします


ただし、YomiTokuでは短編の長さが720ピクセル以上であることを推奨しています。今回はそれを下回るサイズなので、精度が低下する可能性はあります。このあたりも注目すべきポイントです。
図2と図3をダウンロードし、~/Pictures/
$ yomitoku ~/Pictures/sample/horizonal-sample.png -f md -o ~/Documents/ -v --ignore_line_break
わりとわかりやすいオプションですが、horizonal-sample.
第577回と同様の方法で比較して精度を確認してみたところ、図4のようになりました。
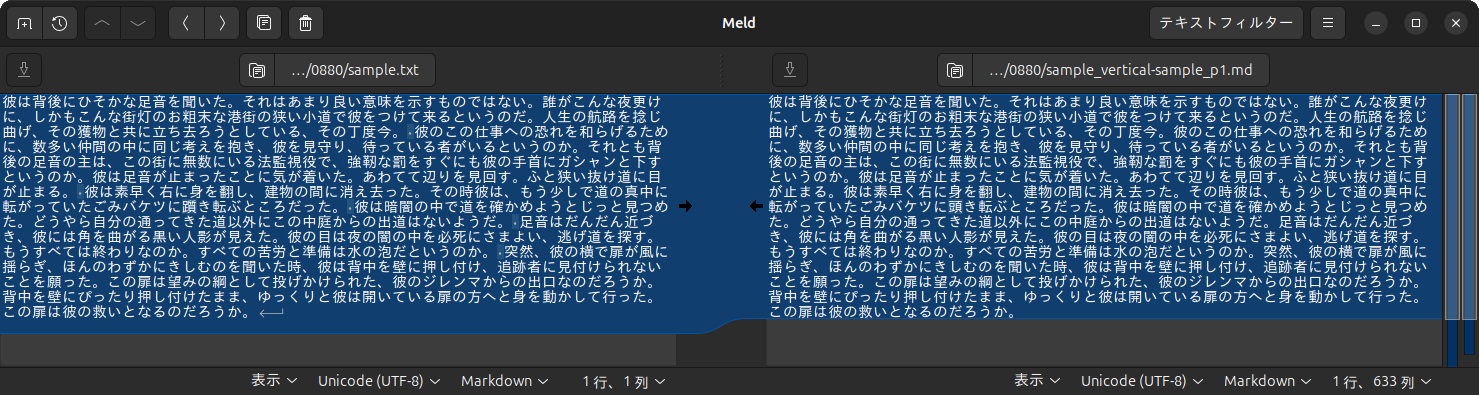
これは縦書きサンプルでの結果ですが、横書きサンプルでも100%の精度でした。前述のとおり画像サイズでは不利でしたが、それでも100%一致し、AIによる画像解析の可能性を大いに感じました。