


今回は、グラフォックボードとしてミドルレンジのGeForce RTX 5060 TiとRadeon RX 9060 XTでllama.
ローカルLLM冬の時代へ
現在、メモリー
この
ただし、今はまだグラフィックボードが品不足というところまではいってません。それがいつまで続くのか、年内までなのか、来年3月までなのかはわかりません。ただ、当面は価格が上がり続けることは概ね確実なので、2年以内にグラフィックボードを新調する予定があるのであれば、今のうちに購入しておくのがいいでしょう。
ローエンドのグラフィックボードに関しては第872回で紹介しました。第868回ではミドルレンジGPUであるRadeon RX 9060 XTを紹介しました。当初は全く予定になかったのですが、このたびGeForce RTX 5060 Ti 16G VENTUS 2X OC PLUSを購入しました。
ミドルレンジGPUのメリット
Radeon RX 9060 XTもGeForce RTX 5060 Tiもミドルレンジではありますが、より細かくはミドルローに分類されます。ミドルハイはRadeon RX 9070シリーズやGeForce RTX 5070シリーズですが、実のところミドルローのほうがおすすめです。理由としては次のとおりです。
まず、手が出しやすい価格であることです。Radeon RX 9060 XTのVRAM 16GBモデルは最安値だと本稿の公開時点で5万円ちょっとです。GeForce RTX 5060 TiのVRAM 16GBモデルは7万円を若干超えるくらいです。ミドルハイになると、Radeon RX 9070 XTで9万円以上、GeForce RTX 5070 Tiで13万円弱と、一気にハードルが上がります。
価格が控えめで性能も控えめだと、大きさと発熱と消費電力も控えめです。第841回で紹介したように、うちにはミドルハイのRadeon RX 7800 XTがありますが、発熱が多くて検証用PCだと熱暴走してしまうので、排熱に力を入れた専用のPCを用意する必要がありました。一方Radeon RX 9060 XTであれば、第868回で紹介したようにDeskMeet X300で延々と負荷をかけ続けても排熱が問題になったりはしませんでした。扱いやすい、というのはとても重要な要素です。
VRAMも8GBでは足りず、16GBでも充分ではありませんが、それでもかなり多くのことができます。
今回使用するPC
今回使用する検証用PCは次のとおりです。
| メーカー | 型番 | 備考 | |
|---|---|---|---|
| CPU | AMD | Ryzen 7 9700X | |
| メモリー | Crucial | CP2K32G56C46U5 | 64GB |
| マザーボード | MSI | PRO B850M-A WIFI | |
| CPUファン | ID-COOLING | IS-67-XT | ファンはP12 PWM PSTに交換 |
| グラフィックボード1 | MSI | GeForce RTX 5060 Ti 16G VENTUS 2X OC PLUS | |
| グラフィックボード2ビデオカード2 | 玄人志向 | RD-RX9060XT-E16GB/ |
|
| SSD1 | MSI | SPATIUM S270 SATA 2. |
|
| SSD2 | Crucial | CT500MX500SSD1 | |
| リムーバブルケース | Silver Stone | SST-FS202 | |
| 電源ユニット | Silver Stone | SST-SX750-G | |
| ケース | Silver Stone | SST-SG11B |
最近マザーボードを入れ替えたことにより、PCIe 5.
なおセキュアブートはオフにしています。
インストールするUbuntuのバージョンは24.
GeForce RTX 5060 Tiに必要なパッケージをインストールする
ではGeForce RTX 5060 TiをUbuntuで使えるようにしていきます。とはいえ例として取り上げるのはGeForce RTX 5060 Tiではあるものの、5000シリーズであれば同じ設定で使用できるはずではあります。
筆者は今まで古いGeForceしか使ってこなかったので知らなかったのですが、最新のGeForce 5000シリーズではオープンソース版のカーネルモジュールを使用する必要があります。以前GeForce 3000シリーズでオープンソース版のカーネルモジュールを使用して画面が正しく出力されなくなって以来、
したがって今回はnvidia-driver-580-openを使用しています
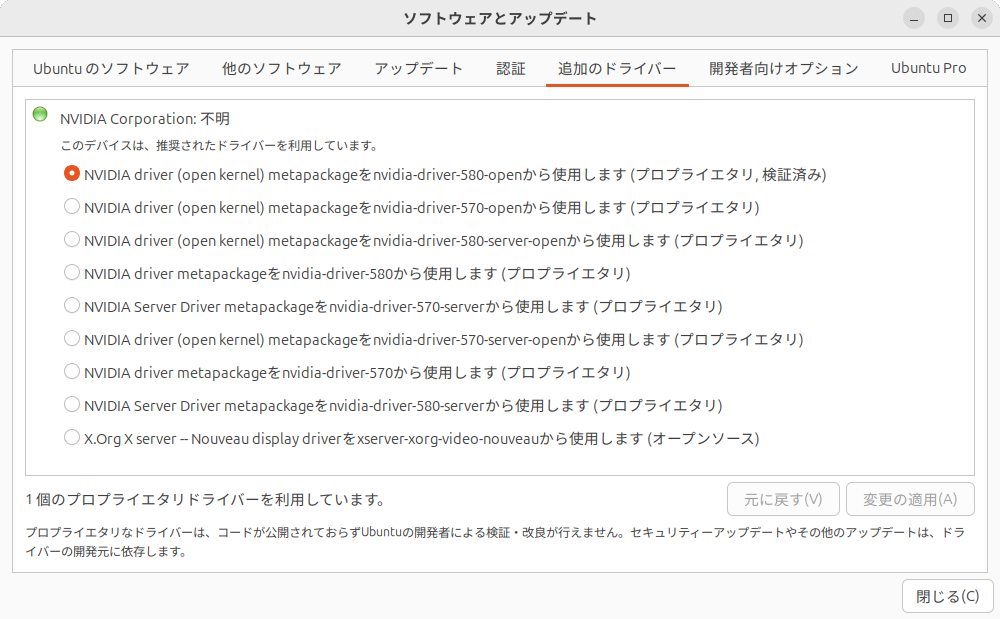
またXセッションではディスプレイの検出に失敗するのか、解像度が1024x768ドットになったので、Waylandセッションにしています。
Ubuntu 24.
それはさておき、次のコマンドを実行してください。
$ ~/Downloads/ $ wget https://developer. download. nvidia. com/ compute/ cuda/ repos/ ubuntu2404/ x86_ 64/ cuda-keyring_ 1. 1-1_ all. deb $ sudo apt install ./ cuda-keyring_ 1. 1-1_ all. deb $ sudo apt update $ sudo apt install cuda-toolkit-13-1
あくまで~/Downloadsがある向けのコマンドなので、ない場合は適宜調整してください。
再起動後、正しくCUDAがインストールされているかどうかはnvidia-smiコマンドでわかります。
Radeon RX 9060 XTに必要なパッケージをインストールする
Radeon RX 9060 XTをUbuntuで使えるようにしていきます。
基本的には第872回と同じですが、今回はカーネルを6.
$ wget https://repo. radeon. com/ amdgpu-install/ 7. 1.1/ ubuntu/ noble/ amdgpu-install_ 7. 1.1. 70101-1_ all. deb $ sudo apt install -y ./ amdgpu-install_ 7. 1.1. 70101-1_ all. deb $ sudo apt update $ sudo apt install python3-setuptools python3-wheel $ sudo usermod -a -G render,video $LOGNAME $ sudo apt install -y rocm amdgpu-dkms
ここで再起動します。
再起動後、正しくROCmがインストールされているかどうかはrocminfoコマンドでわかります。
llama.cppをビルドする
LLMを動かすのにどのエンジンを使うかは悩ましいところですが、今回は第872回と同じllama.
ただしllama.
準備
ではllama.
$ sudo apt install -y git git-lfs cmake g++ libcurlpp-dev $ mkdir ~/git $ cd ~/git $ git clone https://github. com/ ggml-org/ llama. cpp. git $ cd llama. cpp
Vulkan版のビルド
GeForceとRadeonで共通して使用できる、Vulkan版をビルドします。同じ条件での速度の比較を意図しています。次のコマンドを実行してください。
$ sudo apt install libvulkan-dev glslc $ cmake -B build-vulkan -DGGML_VULKAN=ON $ cmake --build build-vulkan --config Release -j 16
CUDA版のビルド
CUDA版は次のコマンドを実行してビルドします。
$ CUDACXX=/usr/local/ cuda-13. 1/ bin/ nvcc cmake -B build-cuda -DGGML_ CUDA=ON $ cmake --build build-cuda --config Release -j 16
ROCm版のビルド
ROCm版は次のコマンドを実行してビルドします。
$ HIPCXX="$(hipconfig -l)/clang" HIP_PATH="$(hipconfig -R)" cmake -S . -B build-rocm -DGGML_ HIP=ON -DGPU_ TARGETS=gfx1200 -DCMAKE_ BUILD_ TYPE=Release $ cmake --build build-rocm --config Release -j 16
ベンチマーク
ビルドしたllama.
次のコマンドを実行しました。
$ ./build-vulkan/ bin/ llama-cli -m ~/Downloads/ gpt-oss-120b-Q4_ K_M-00001-of-00002. gguf -p "偏りのないコインを表が出るまで投げ続け、表が出たときに、賞金をもらえるゲームがあるとする。もらえる賞金は、1回目に表が出たら1円、1 回目は裏が出て2回目に表が出たら倍の2円、2回目まで裏が出ていて3回目に初めて表が出たらそのまた倍の4円、3回目まで裏が出ていて4回 目に初めて表が出たらそのまた倍の8円、というふうに倍々で増える賞金がもらえるというゲームである。ここで、このゲームには参加費 ( =賭け金) が必要であるとしたら、参加費の金額が何円までなら払っても損ではないと言えるだろうか。" -no-cnv --n-gpu-layers 99 --n-cpu-moe 28
表にしてまとめると次のようになりました。単位はトークン/秒です。
| GPU | バックエンド | プロンプト | 結果 |
|---|---|---|---|
| GeForce RTX 5060 Ti | Vulkan | 59. |
27. |
| GeForce RTX 5060 Ti | CUDA | 132. |
30. |
| Radeon RX 9060 XT | Vulkan | 65. |
25. |
| Radeon RX 9060 XT | ROCm | 84. |
25. |
CUDAはダントツの速度を叩き出しています。ROCmはもう少し速度が出てもよさそうな気がしますが、llama.
llama-server
llama.
例として、次のコマンドでサーバーを起動します。
$ ./build-cuda/bin/llama-server -m ~/Downloads/gpt-oss-120b-Q4_K_M-00001-of-00002.gguf --ctx-size 0 --jinja -ub 4096 -b 4096 -ngl 99 --n-cpu-moe 34 --host 0.0.0.0 --port 8080 --chat-template-kwargs '{"reasoning_effort": "medium"}' --temp 1.0 --top-p 1.0
細かいオプションの説明をしだすとキリがないので省略しますが、--n-cpu-moeの値がベンチマークのときより増加しています。これはベンチマークと同じ値だとメモリー不足でサーバーが起動しないからで、この値を増やすとGPUへの負荷が減ります。ということはその分CPUの負荷が増えるということであり、処理が遅くなります。
Firefoxを起動し、--portの値
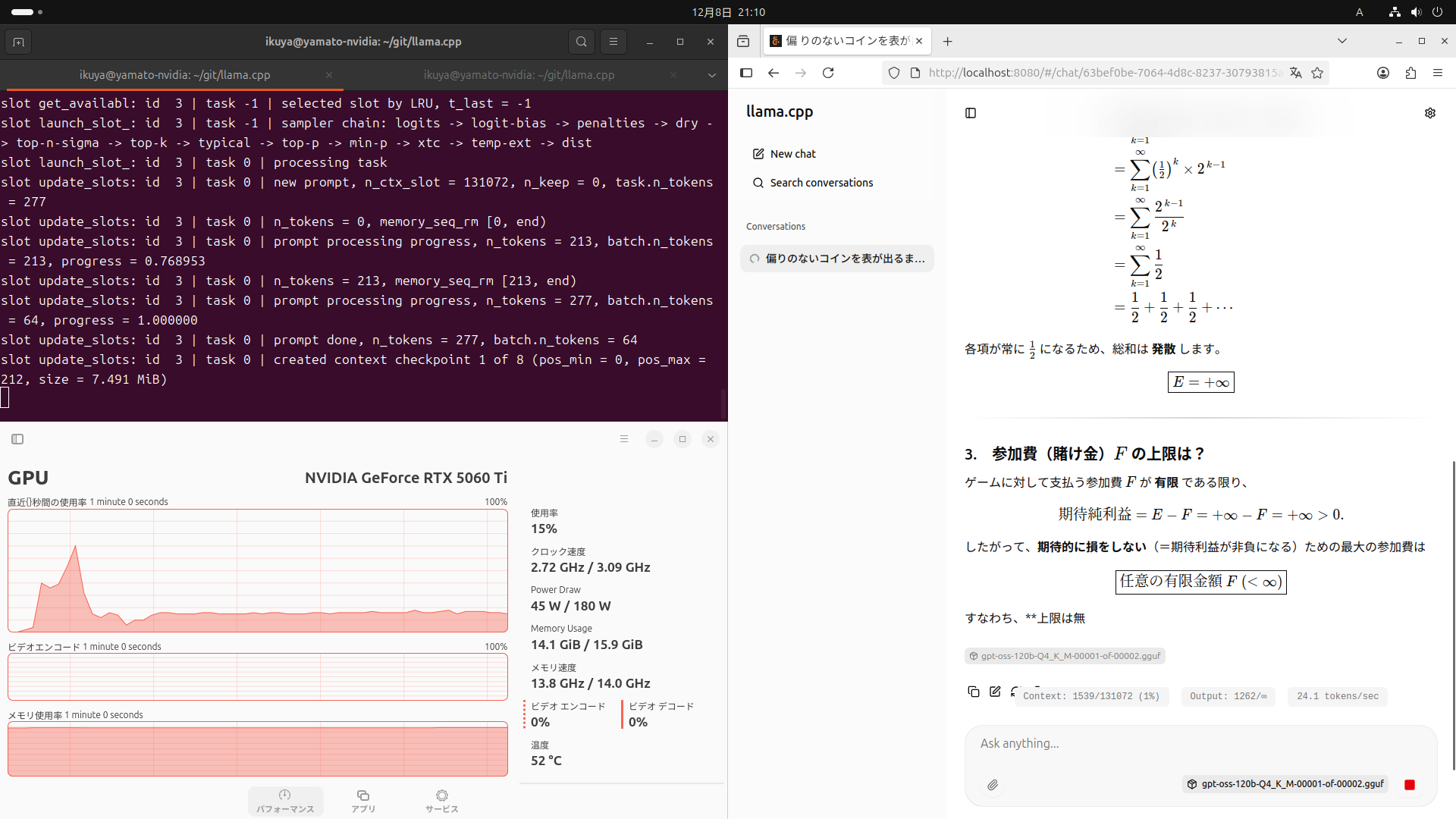
実際に動作させると、右下のとおり