



はじめに
今回のテーマはデータ分析、データ分析ユースケースに利用可能なサービスとサービスの使い分けについて解説します。
第2回の
AWSには、保存されたデータを目的に応じたサービスを利用することで、柔軟でスケーラブルなデータ分析を実現することが可能です。AWSは、あらゆるデータ分析のニーズに適合する最も幅広い分析サービスを提供しており、どんな規模・
データ分析ユースケース
データ分析者は、オブジェクトストレージやデータベース、データウェアハウスなどのデータストアに収集・
図1は、データ分析基盤を構成する際の実装アーキテクチャの1つであるラムダアーキテクチャです。集積された全データを対象にデータを加工・
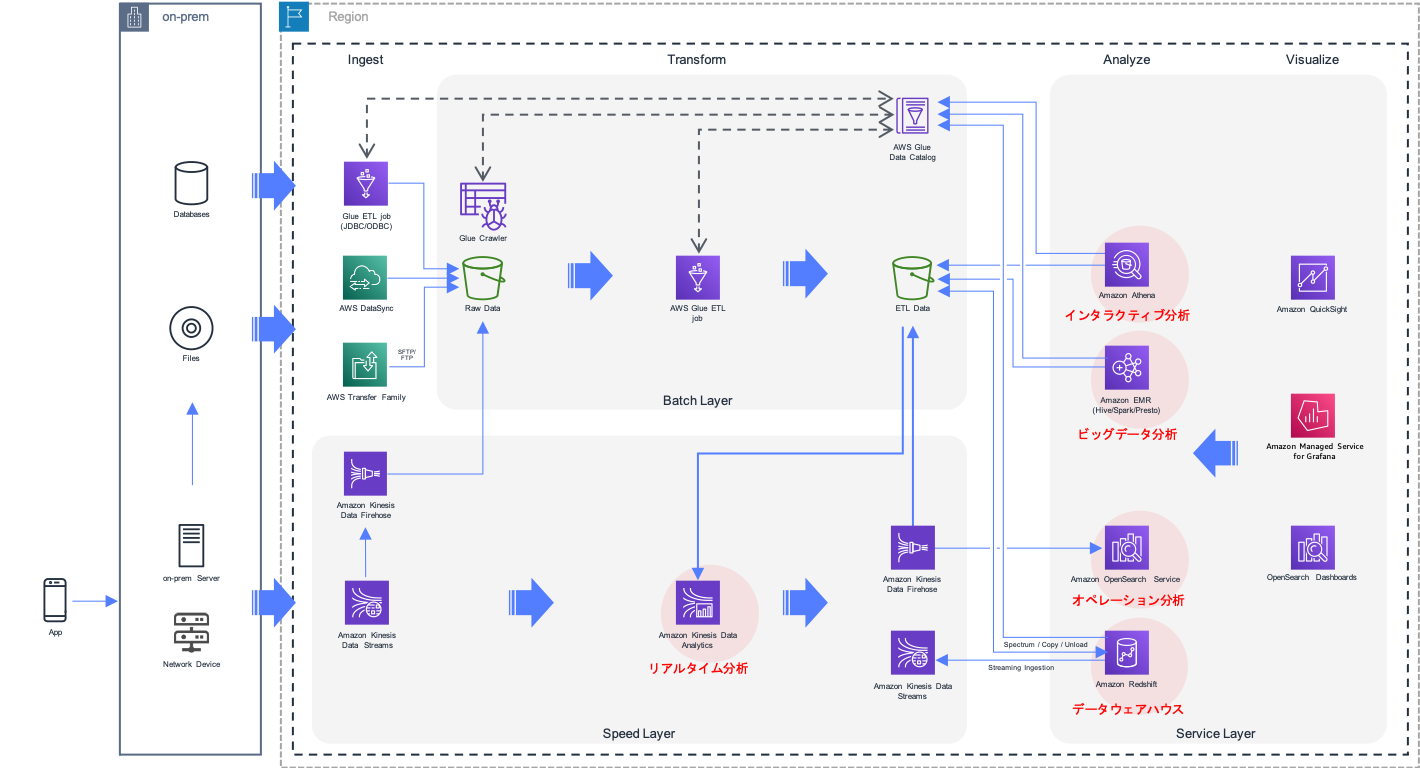
ラムダアーキテクチャを構成するために活用される分析ユースケースについて、それぞれ解説していきます。
- データウェアハウス
- インタラクティブ分析
- ビッグデータ分析
- オペレーション分析
- リアルタイム分析
データウェアハウス
データウェアハウスは、数百ギガバイトからペタバイトスケールの大規模データを分析するためのプラットフォームです。データウェアハウスの多くがリレーショナルデータベースと同様に正規化されたデータをテーブル内に持ち、SQLでの分析をサポートしています。BIツールなどのユーザーインターフェイスを備えた分析ツールや、アプリケーションから頻繁に分析用のクエリが発行されるようなケースで特に力を発揮します。分析言語には標準的なSQLを利用できます。
データウェアハウスの多くは複数のノードで分散処理を行う前提でアーキテクチャーが設計されています。エンジンに特化した独自のデータ構造を採用するほか、独自のキャッシュ機構を備えているなど、複雑なクエリを素早く処理できるよう最適化が図られています。バッチビュー、リアルタイムビューとして継続的に保存されるデータや低レイテンシーでストリームに流れるデータを参照して、単体でラムダアーキテクチャを構築することが可能なデータウェアサービスがAmazon Redshiftです。
Amazon Redshiftは、高速でフルマネージド型のコスト効率にも優れたデータウェアハウスサービスです。ペタバイト規模のデータウェアハウスとしてだけでなく、エクサバイト規模のデータレイクに保管されたバッチビューに対する分析や配信ストリームを対象としたリアルタイム分析を1つのサービスで実現できます[1]。さらに、別のRedshiftクラスターに保存されたデータやAmazon Aurora/
インタラクティブ分析
インタラクティブ分析は分析者が必要に応じてオンデマンドにクエリを投げてデータを分析する手法です。バッチレイヤで実施されるような分析内容が決まっているデータ分析と異なり、今あるデータに対して、マーケットリサーチやビッグデータ処理の現場で生じるオンデマンドな要件に基づく集計や分析結果を、スピード感を持ってインタラクティブに取得したい場合によく利用されます。バッチビュー、リアルタイムビューとして継続的に保存されるデータを対象にインタラクティブ分析可能なサービスがAmazon Athenaです。分析言語には標準的なSQLを利用することができます。
Amazon Athenaを使用すると、Amazon S3に保管された構造化/半構造化データに対してスキーマを定義するだけで簡単にSQLでデータを分析できます。Amazon Athenaはサーバーレスなサービスなので、インフラストラクチャの構築や運用管理も不要です。
ビッグデータ処理
ペタバイト/エクサバイト規模のビッグデータを処理する場合、どんなに高性能なサーバーを用意しても1台では処理に限界があり、想定時間内に処理を完了できません。Hadoop、Spark等に代表される分散処理基盤を利用すると、ビッグデータを複数のサーバに分けて並列処理できるので、この問題を解決できます。
Hadoopは汎用的な分散処理基盤となっており、さまざまなオープンソースフレームワークが提供する多様な分析手段により、構造化/半構造化データに対するクエリエンジン、マルチメディアデータ
Amazon EMRは、Hadoopをベースにさまざまなビッグデータフレームワークの実行・
オペレーション分析
アプリケーション、サーバー、クラウドインフラストラクチャ、IoTとモバイルデバイス、DevOps、マイクロサービスアーキテクチャなど、様々なITトレンドが生成するログ情報を分析することで、運用効率の改善や顧客体験の向上に役立つインサイトを得ることが可能です。
継続的に発生するログ情報はバッチレイヤ、スピードレイヤを経由して集約され、分析されます。リアルタイムビューを継続的に集約、可視化・
Amazon OpenSearch Serviceは、100%オープンソースの検索および分析スイートである OpenSearchをOpenSearchクラスターの運用に関する深い専門知識を構築することなく利用できるマネージドサービスです。Amazon OpenSearch Serviceを利用すると、コスト効率良くデータを運用するためのストレージオプションを利用できるため、大量のログデータを対象としたログ分析を実現できます。OpenSearch Dashboardsを利用した継続的なログデータの分析と可視化、異常発生時にアラートを通知するなど、ログ分析に求められるさまざまな機能を実現することが可能です。
AWSが提供するさまざまなサービスとの親和性が高く、例えば、Amazon Kinesis Data Firehoseを利用すると、ニア・
リアルタイム分析
リアルタイム分析を利用すると、サーバーで発生するログ情報やモバイルデバイスで取得可能な位置情報、アプリ利用で発生するメッセージやイベント情報など、時々刻々リアルタイムに発生する情報を鮮度高く処理できます。よって、データ駆動型の意思決定やマーケティング施策に欠かせない分析手法となっています。
その一方で、IoTやスマホなど、デバイスの増加やデバイスの利用動向により、データの流量がダイナミックに変化するため、必要となる分析リソースに弾力性が求められます。分析リソースは大量に発生するデータを配信するデータストリームとストリームに流れるデータを継続的に処理する処理エンジンの2つの要素で構成されます
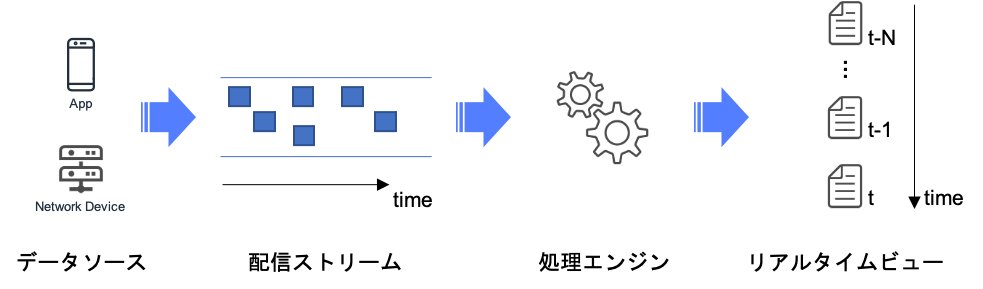
AWSには、配信データストリームを実現するサービスとして以下の選択肢があります。
- Amazon Kinesis Data Streams(KDS)
- Amazon Kinesis Data Firehose(KDF)
- Amazon Managed Streaming for Apache Kafka(Amazon MSK)
同様に、ストリーミングデータ処理エンジンに利用可能なサービスには、以下の選択肢があります。
- Amazon Kinesis Data Analytics
- AWS Glue(Streaming Jobs)
- Amazon EMR(Spark Streaming/
Flink)
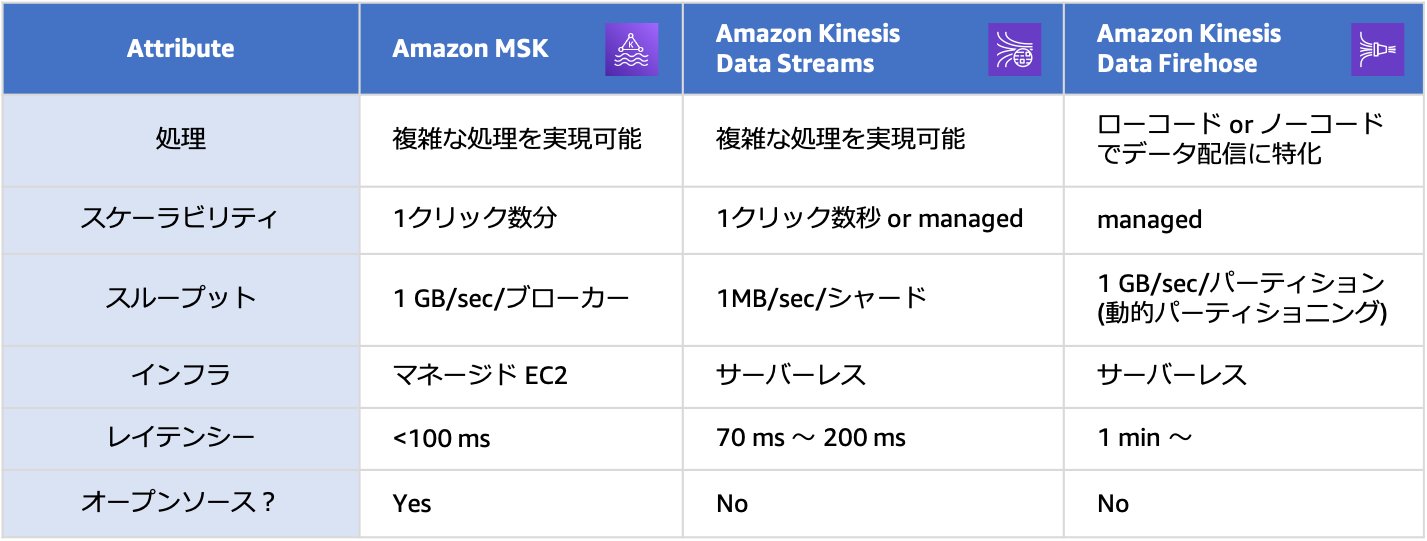
構築する基盤の要件に応じて、適切なサービスを取捨選択し、利用できます。配信データをバッファすることによる遅延が許容できない場合はKDSかMSKを、許容できる場合はKDFを選択してください。また、リアルタイム処理で複雑な処理を実現したい場合はKDSかMSKを、データ配信に特化して簡単にリアルタイム処理を実現したい場合はKDFを利用できます。オープンソースベースのインテグレーションにはMSK、AWSネイティブベースのインテグレーションにはKDSがそれぞれ親和性が高くなっています。
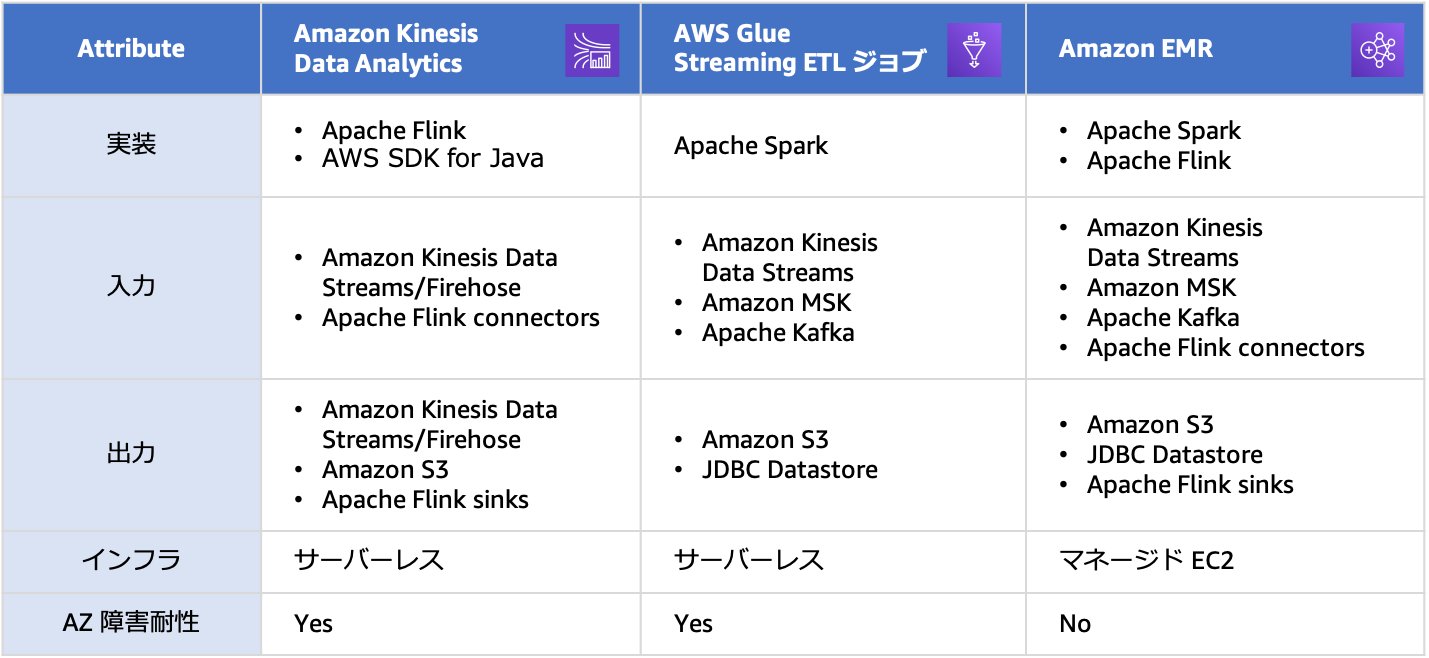
処理エンジンでは、実装アプリケーションフレームワークにSparkとFlinkどちらを利用するかで選択肢を絞ることができます。その上でデータソースにどの配信ストリーム実装を利用するかと処理エンジンの運用効率を踏まえて、利用するサービスを検討してください。
表1、表2に配信ストリームとストリーミング処理エンジンそれぞれについて、サービスの使い分けについてまとめます。
データ分析サービスの使い分け/使い方
次に、データ分析サービスの使い分けと、それぞれの使い方を見ていきます。
クエリエンジンの使い分け
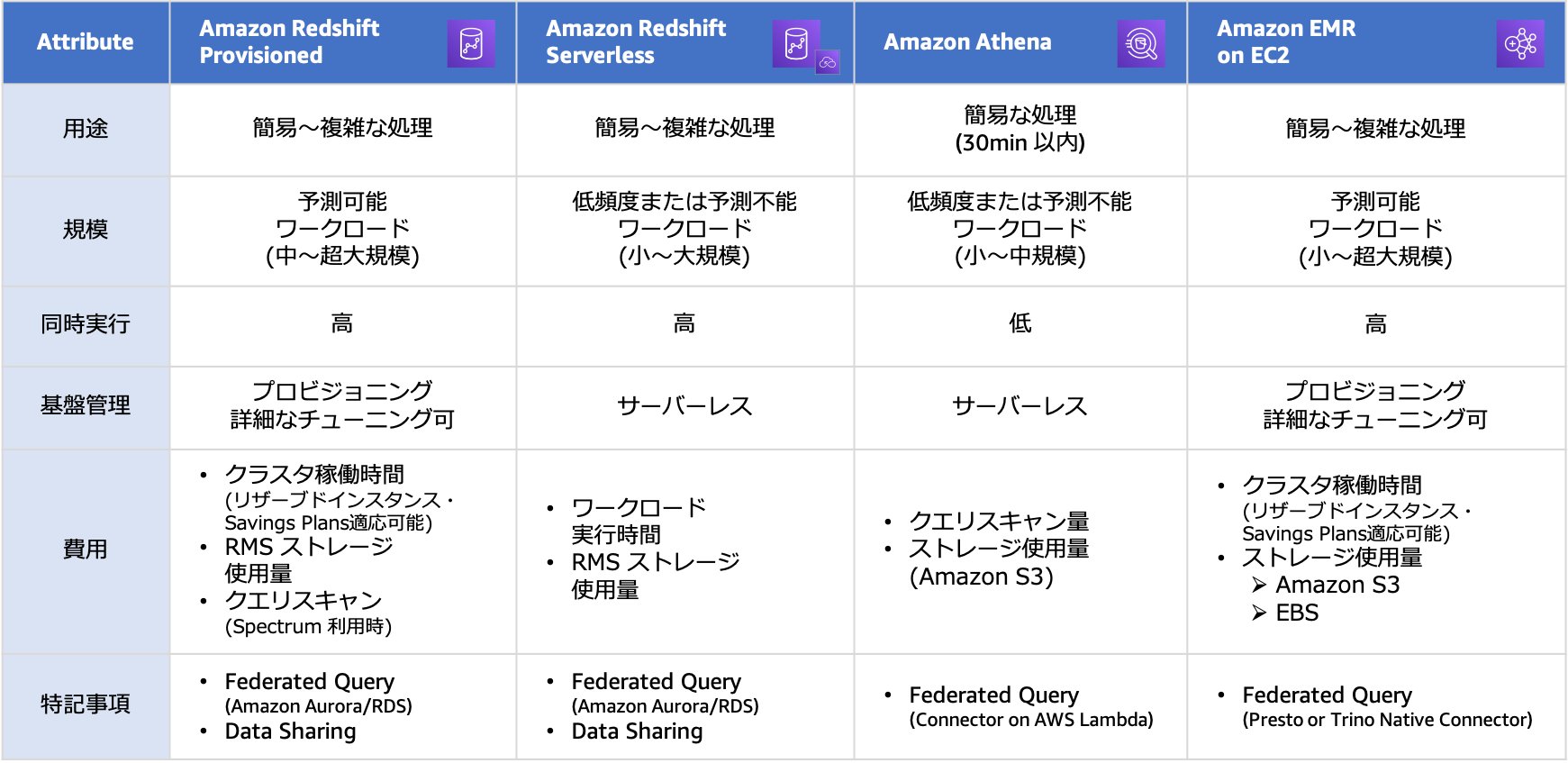
ユースケースの中で分析サービスに求められる要件を整理した上で、ノックアウト条件にヒットせず、コスト効率の良いサービスを選択する必要があります。データウェアハウスやインタラクティブ分析のユースケースではクエリエンジンとしてAmazon RedshiftとAmazon Athenaを比較検討することが多くあります。また、ビッグデータ処理をSQL処理で実現可能な場合、Amazon EMRも選択肢として検討することが可能です。
表3に各サービスの特徴をまとめます。クエリエンジンの用途として
- リソースベース
- データ分析に必要なコンピューティングリソースとストレージリソースを利用した分の従量課金モデル
- データスキャンベース
- データ分析時に発生するデータスキャン量とストレージリソースに対する従量課金モデル
ビッグデータ処理における実装
Hadoop、Spark等に代表される分散処理基盤を利用すると、データウェアハウスのアプローチで扱えない規模のビッグデータを現実的な処理時間で解決したり、一時的に大量のリソースを確保し、ビッグデータ処理を短期間で解決できます。その一方で、ビッグデータを効率よく、かつ安定して処理を実施させるためには、処理効率やメモリ管理を意識した難易度の高いプログラミングと分散処理基盤自体のチューニングに関するスキルが必要となります。
これらに対応するには専門的な知識を保有したエンジニアが必要となり、人材確保・
SQL実装を採用することで以下のようなメリットを得られます。
- 分散処理を扱えるエンジニアと比較して、圧倒的に人材確保・
人材育成が容易 - 特別なプログラミング知識が不要
- SQLが標準でサポートしない計算処理を利用する要件が発生した場合はプログラミングが必要になります。
まとめ
今回はデータ分析基盤を構成する実装アーキテクチャの1つであるラムダアーキテクチャを例に、データ分析ユースケースとそれらに利用可能なサービス、サービスの使い分けについて解説してきました。
次回はこれまでの連載を通じて得られるデータやデータ分析結果を活用することをテーマにお届けする予定です。ご期待ください。