※
2020年10月22日に論文共有サイトarXivに掲載された1本の論文がコンピュータビジョン分野に衝撃を与えました。ViT
ViTは自然言語処理におけるTransformerより簡素な構造でありながら、画像のコンテンツを理解し、適切なラベルを返却するという画像識別問題において、従来法を置き換える十分な精度に到達していると主張しました。従来法とひと言で言いましたが、画像識別におけるCNN
機械学習の分野では、たった1本の論文がその後の流れを大きく変えることがありますが、ViT論文は間違いなくコンピュータビジョンの研究動向を劇的に塗り替えました。実際に、2021年の大きな研究トレンドは、いかにTransformerをコンピュータビジョン分野に浸透させるかの一色になり、その年の秋に開催されたICCV 2021のBest Paper Award
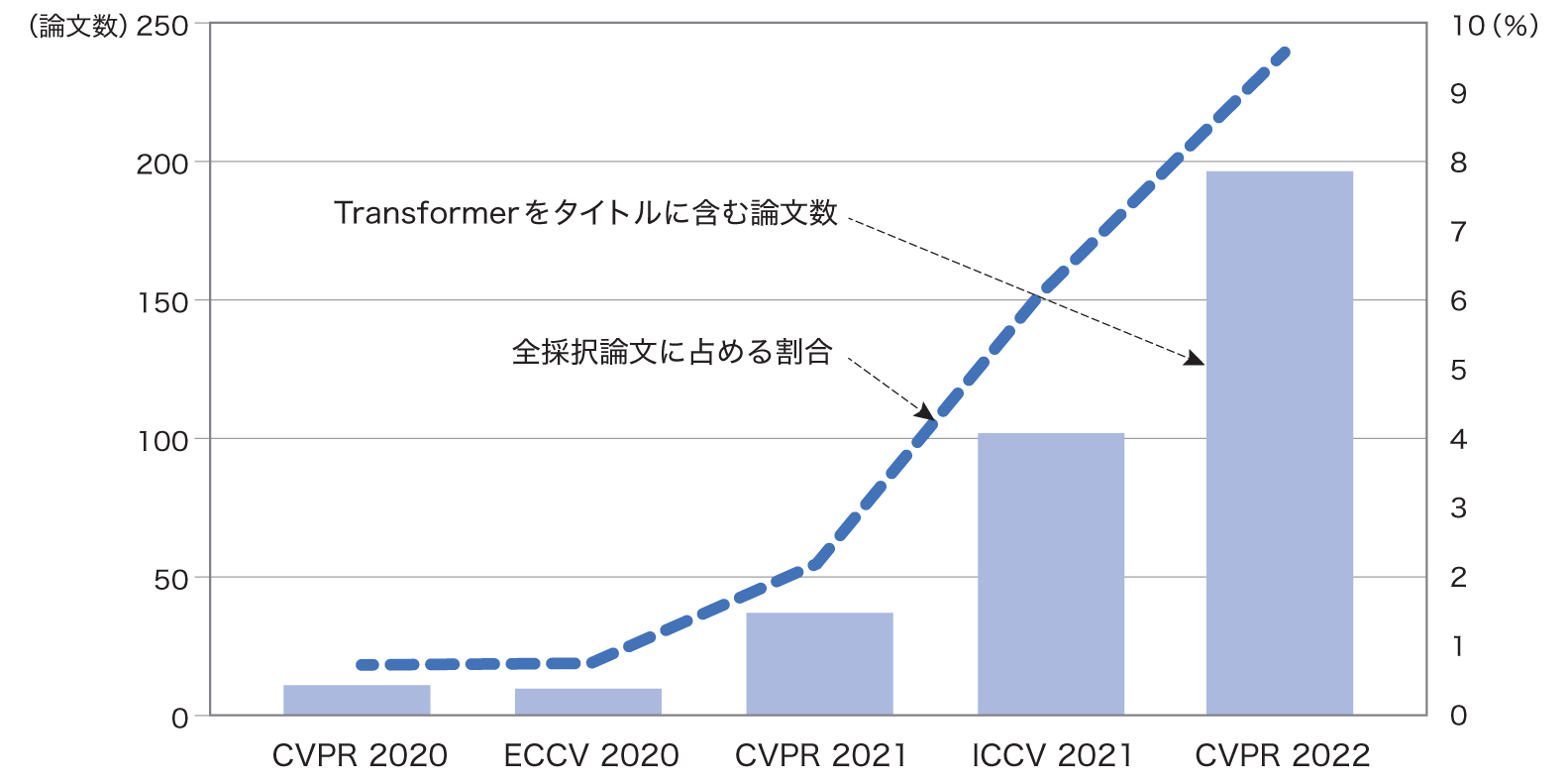
さて、2022年9月に発売となった
執筆時点においてもめまぐるしく変化するViTに関する動向を紐解いていきます。ViT論文がコンピュータビジョン分野の研究を加速させてきたように、本書、通称ViT-Book
2022年8月 片岡裕雄
参考文献
- [Dosovitskiy21]
- [Krizhevsky12]
- [Liu21]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, et al. "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" ICLR, 2021.
Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton "ImageNet Classification with Deep Convolutional Neural Networks" NIPS, pages 1097-1105, 2012.
Ze Liu, Yutong Lin, Yue Cao, et al. "Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows" ICCV, pages 10012-10022. 2021.