目次
第1章 文字とコンピュータ
1.1 コンピュータで文字を扱う基本
- 文字コードとフォント
- 図形を交換するのでなく符号を交換する
- 文字の形の細部は伝わらない
1.2 文字を符号化するということ
- コンピュータで情報を扱う基礎
- 文字を符号化する例
1.3 文字集合と符号化文字集合
- 何文字必要か
- 文字の集合
- 文字の集合に符号を振る
- 符号化文字集合とは
- 実用的な符号化文字集合の例
- 一意な符号化 文字コードの原則
- 符号化文字集合を実装するとは
- 文字化け
- 外部コードと内部コード
- 規格における定義 符号化文字集合符号
1.4 制御文字 ……文字ではない文字
- 文字コードにあるのは文字だけではない
- おもな制御文字
1.5 文字コードはなぜ複雑になるのか
- 文字コードを複雑化させる二つの理由
- 過去の経緯の積み重ね
- 文字そのものの難しさ
- 文字コードの複雑さを理解するために
1.6 まとめ
第2章 文字コードの変遷
2.1 最もシンプルな文字コード ……ASCIIISO/IEC 646
- 7ビットの1バイトコードで文字を表すASCII
- ASCIIの各国用の変種 各国語版ISO/IEC 646
- ISO/IEC 646とJIS X 0201
2.2 文字コードの構造と拡張方法を定める ……ISO/IEC 2022
- ISO/IEC 2022の登場 8ビットコード2バイトコード
- ASCIIを拡張する
- 8ビットの使用 ISO/IEC 2022の枠組みCL/GLCR/GR
- 符号化文字集合の呼び出しの概念
- 複数バイト文字集合
- 符号化文字集合の組み合わせ・切り替え
- ISO/IEC 2022とエスケープシーケンス
- 2022≠エスケープシーケンスによる切り替え
- ISO/IEC 2022と符号化方式
- ISO/IEC 2022とエスケープシーケンス
2.3 2バイト符号化文字集合の実用化 ……JIS X 0208各種符号化方式
- JIS X 0208 漢字を扱う
- 各種「符号化方式」の成立
- 1バイトコードに2バイトコードを組み合わせたい
- Shift_JISやEUC-JPISO-2022-JPの登場
- 東アジアでの普及
2.4 1バイト符号化文字集合の広がり ……ISO/IEC 8859Latin-1
- ヨーロッパ各地域向けの文字コード
- ISO/IEC 8859ISO/IEC 8859-1Latin-1
- 1バイト文字集合の乱立
2.5 国際符号化文字集合の模索と成立 ……UnicodeISO/IEC 10646
- 世界中の文字を一つの表に収める
- ISO/IEC 10646とUnicodeの誕生と統合
- Unicodeの拡張と各種符号化方式の成立 UTF-16UTF-8
- 国際符号化文字集合の現状
- Unicodeの使用状況 OSの内部コードやWebページとその他の状況
2.6 まとめ
- Column 字形と字体
- Column 常用漢字表の改正と文字コード
第3章 代表的な符号化文字集合
3.1 ASCIIとISO/IEC 646 ……最も基本的な1バイト文字集合
- ASCIIとISO/IEC 646国際基準版
- 各国版のISO/IEC 646
3.2 JIS X 0201 ……ラテン文字と片仮名の1バイト文字集合
- JIS X 0201の概要
- ラテン文字集合
- JIS X 0201の片仮名集合濁点・半濁点
- ASCIIとの違い 円記号とバックスラッシュオーバーラインとチルダ
3.3 JIS X 0208 ……日本の最も基本的な2バイト文字集合
- JIS X 0208の概要 ISO/IEC 2022準拠
- 符号の構造 2バイトのビット組み合わせ
- 文字集合の特徴
- 記号類
- ギリシャ文字
- キリル文字
- ラテン文字
- 平仮名・片仮名
- 漢字 第1水準第2水準
- 過去の改正の概略
- 1983年改正
- 字体の変更(簡略化)と符号位置の入れ替え
- 1990年改正
- 1997年改正 包摂規準
- 包摂規準の明示
- JIS X 0208(97JIS)の包摂規準の活用
- JIS X 0208(97JIS)の包摂規準の生い立ち
- 漢字の包摂規準を理解する
- 漢字の典拠調査 幽霊漢字の退治
- 1983年改正
- JIS X 0208:1997の符号化方式
- 外字・機種依存文字の問題
3.4 JIS X 0212 ……補助漢字
- JIS X 0212の概要
- 文字集合の特徴
- 非漢字
- Column 「Unicodeで(他の符号化文字集合を)実装」という表現の問題
- 漢字
- JIS X 0212と符号化方式 Shift_JISで扱えない
3.5 JIS X 0213 ……漢字第3・第4水準への拡張
- JIS X 0213の概要
- 漢字集合1面漢字集合2面
- 文字集合の特徴
- 一般の印刷物でよく使われる記号類
- 13区の機種依存文字と互換の文字
- ラテン文字・発音記号
- 日本語のローマ字表記に必要な文字
- 発音記号として使われる文字
- その他のダイアクリティカルマーク付きの文字など
- 合成用のダイアクリティカルマーク
- ASCIIとの互換性のための文字
- アイヌ語表記用片仮名
- 鼻濁音表記用の平仮名・片仮名など
- 漢字(第3・第4水準)
- 地名や人名学校教科書に使われる漢字
- 収録された文字の収集にあたって
- 妛問題の字体の新規追加による解決
- 199の包摂規準
- 人名用漢字のすべて JIS X 0208で包摂されていた微小な差を分離したもの
- 1983年改正で字体が大きく変更された漢字29文字の変更前の字体
- 漢字のへんやつくりなどの字体記述要素
- 符号化方式
- 符号化方式をめぐる論議 規定か参考か
- 2004年改正の影響 表外漢字字体表と例示字形
- Unicodeとの対応関係 表外漢字UCS互換
- ソフトウェアのJIS X 0213対応状況
3.6 ISO/IEC 8859シリーズ ……欧米で広く使われる1バイト符号化文字集合
- ISO/IEC 8859(シリーズ)の概要
- Latin-1 ISO/IEC 8859-1
- ノーブレークスペース(NBSP)とソフトハイフン(SHY)
- Latin-2 ISO/IEC 8859-2
- その他のパート
3.7 UnicodeとISO/IEC 10646 ……国際符号化文字集合
- UnicodeおよびISO/IEC 10646(UCS)の概要
- 符号の構造 UCS-4UCS-2BMP
- Unicodeの符号位置の表し方
- 基本多言語面(BMP)
- その他の面
- 面01 SMP
- 変体仮名
- 面02 SIP
- 面0E
- 結合文字 1文字が1符号位置ではない
- 既存の符号化文字集合との関係
- Unicodeにおける文字名の定義 各文字に一意な名前を与える
- Column ちょっと気になるUnicodeの文字名
- ISO/IEC 8859-1との関係
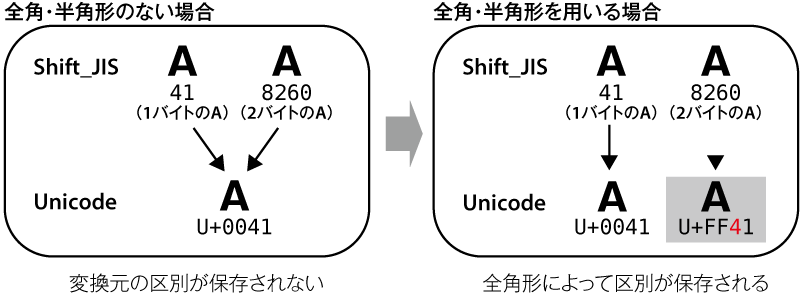
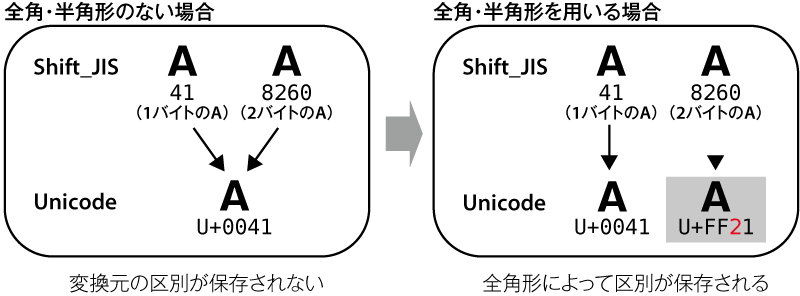
- 全角・半角形
- 漢字統合 CJK統合漢字
- 原規格分離規則
- 統合漢字の数
- 漢字統合と適切なフォントの選択
- 互換漢字
- 互換漢字の領域
- 互換漢字と正規化
- JIS X 0213との関係 プログラムで処理する上での注意点
- ❶BMP以外の面の漢字の存在
- ❷結合文字の使用の必要
- ❸互換漢字の正規化の問題
- 絵文字
- 絵文字とは
- 符号位置概要
- 複数符号位置による装飾
- 国旗の特殊な符号化
- 絵文字の形の違い
- 絵文字に未来はあるか
- Column UnicodeとUTF-8とUCS-2の関係
第4章 代表的な文字符号化方式
4.1 JIS X 0201の符号化方式
- JIS X 0201の符号化方式の使い方
- 8ビット符号
- 7ビット符号
4.2 JIS X 0208の符号化方式
- JIS X 0208で定められた符号化方式
- 漢字用7ビット符号
- 符号の構造
- 漢字用7ビット符号の特徴
- 適した用途
- EUC-JP
- 符号の構造
- 国際基準版・漢字用8ビット符号との関係
- EUC-JPの特徴と注意
- 重複符号化の問題
- 適した用途
- 符号の構造
- ISO-2022-JP
- 符号の構造
- 符号の性質
- 適した用途
- Shift_JIS
- 符号の構造
- Shift_JISの計算方式
- Shift_JISの問題点
- 重複符号化の問題
- 適した用途
- 機種依存文字付きの変種
4.3 Unicodeの符号化方式
- UTF概説
- UTF-16
- 符号の構造
- サロゲートペア
- UTF-16の計算方法
- UCS-2との関係
- UTF-16のバイト順の問題 ビッグエンディアンとリトルエンディアン
- BOM(バイト順マーク)
- 適した用途
- UTF-32
- 符号の構造
- UCS-4との関係
- UTF-32の特徴
- 適した用途
- 符号の構造
- UTF-8
- 符号の構造
- 計算方法
- ASCIIとの互換性 UTF-8の特徴
- 冗長性の問題
- BOM付きUTF-8の問題
- CESU-8とModified UTF-8
- 適した用途
- 符号の構造
- Column 機種依存文字における重複符号化
第5章 文字コードの変換と判別
5.1 コード変換とは
- なぜ変換が必要か
- 変換のツール
- iconv
- 変換できない場合
- nkf
- iconv
- 変換の原則
- 異なる文字集合体系の間の変換の問題
- コード変換と文字変換
5.2 変換の実際 ……変換における考え方
- コード変換の処理方法
- アルゴリズム的な変換
- JIS X 0208の符号化方式の変換
- ISO-2022-JPとEUC-JPの間の変換 エスケープシーケンスと0x80の足し引き
- Shift_JISの関係する変換 区点番号を介した計算
- JIS X 0201とASCIIの違いの問題 Shift_JISの``0x5C````0x7E``
- 文字コードの定義に忠実なコード変換とその問題
- Unicodeの符号化方式の変換
- UTF-8からの変換
- UTF-16からの変換
- JIS X 0208の符号化方式の変換
- テーブルによる変換
- JIS X 0208とUnicodeの間の変換
- JIS X 0208とASCII/JIS X 0201の間の変換
- JIS X 0201ラテン文字集合の変換の例題
- ハイフンマイナスの問題
- JIS X 0201片仮名集合の場合
- 変換の必要性 使い勝手の向上のために
5.3 文字コードの自動判別
- 自動判別の例
- 判別のツール nkf
- なぜ自動判別できるか
- BOMによる判別
- エスケープシーケンスによる判別
- バイト列の特徴を読む EUC-JPとShift_JISの判別例
- 自動判別を助けるテクニック
- 自動判別の限界
5.4 まとめ
第6章 インターネットと文字コード
6.1 電子メールと文字コード
- メールの基本はASCII 日本語は7ビットのISO-2022-JPで
- MIME
- メールを多言語に拡張する
- charsetパラメータで文字コードを指定する
- charsetパラメータの値
- 誤ったcharset指定
- Column character setという用語
- テキストをさらに符号化する
- Content-Transfer-Encodingフィールド
- quoted-printable
- base64
- base64による符号化のしくみ
- ヘッダの符号化 B符号化とQ符号化
- nkfによる復号
- 添付ファイル名の符号化
- 添付ファイル名のトラブルの原因
- 添付ファイル名の文字化けへの対処法
- 日本語メールの符号化の現在
6.2 Webと文字コード
- HTML
- HTMLで用いる文字
- SGMLとしての背景
- HTMLの文字参照
- 文字コードの指定方法 head要素の中のmeta要素
- lang属性の影響
- 統合漢字を描画し分ける
- 言語情報は書体選択の役に立つか
- CSS
- 文字コードの指定方法
- Unicode文字の参照
- XML
- XMLで用いる文字
- XMLの文字参照
- 文字コードの指定方法
- XML宣言
- XHTMLの場合
- YAMLとJSON
- URL
- URL符号化
- HTML・XMLの中のURL
- URL符号化
- HTTP
- HTML文書内部の文字コード指定が抱える問題点
- HTTPヘッダによる文字コードの指定
- Webサーバにおける設定
- HTTPヘッダの確認方法
- HTMLフォーム(CGI)
- フォームから入力されるテキストの文字コード
- 送信用の文字コードで符号化できない文字の扱い
6.3 まとめ
第7章 プログラミング言語と文字コード
7.1 Java ……内部処理をUnicodeで行う
- Javaにおける文字はすべてUnicode
- Javaの文字列と文字
- StringクラスとCharacterクラスとchar型
- ソースコードの中の文字
- コンパイル時のコード変換
- Unicodeエスケープ
- JavaはUnicodeを知っている
- 文字の属性を調べる
- 大文字・小文字 Character.isLowerCase(char)メソッド他
- 数字・文字 Character.isDigit(char)メソッド
- Unicodeブロック Character.UnicodeBlockクラス
- サロゲートペアにまつわる問題 char単位で文字を扱うメソッド
- サロゲートペアへの対応 charからintへ
- 入出力における文字コード変換
- Reader/Writerクラスによる変換
- 文字コードを指定した入出力 InputStreamReader/InputStreamWriterクラス
- Javaで扱える文字コード
- プラットフォームのデフォルトの文字コードを得る
- デフォルトの文字コードを指定する
- プロパティファイルの文字コード
- native2ascii
- プロパティエディタ プロパティファイル編集用のツール
- XML形式のプロパティファイル
- Propertiesクラス
- リソースファイル プロパティファイルを国際化のために用いる
- JSPと文字コード
- pageディレクティブによる指定
- Windowsの場合の問題 MS932変換表とSJIS変換表
- よく問題になる例 〜(波ダッシュ)
- 3つの対処法 入力/出力におけるUnicode変換の食い違いを解消する
- ❶入力時の変換をSJIS変換表に揃える
- ❷MS932変換表を使う
- ❸Javaプログラムで置換したうえでSJIS変換表で出力する
- 文字コード変換器の自作方法
- ソートの問題 テキスト処理❶
- 文字コードによるソート順
- 文字コード順以外によるソートの必要性 言語や国・地域を考慮する
- Collatorクラスの使用
- CollationKeyによる性能改善
- 自然な区切り位置の検出 テキスト処理❷
- 何が問題か Javaのcharと結合文字やサロゲートペア
- BreakIteratorクラス 適切な区切り位置を検出する
7.2 Ruby 1.8 ……シンプルな日本語化
- バージョン1.8までのRubyはASCIIが基本
- Ruby 1.8の文字列
- 文字列の長さ
- バイト列としての操作
- 文字列の操作
- 文字列の比較とソート
- jcodeによる複数バイト文字対応
- 文字コードの指定
- 指定方法 -Kオプション$KCODE
- 正規表現のマッチング 文字コードの指定を適切に行う
- $KCODEによる違い
- 正規表現ごとの文字コード指定
- 文字列を文字単位に切り分けるイディオム
- 文字コードの指定を間違うと何が起こるか
- JIS X 0213を使う
- コード変換ライブラリ
- NKF
- コード判別
- Kconvクラス
- Iconvクラス
- NKF
7.3 Ruby 1.9以降 ……CSI方式で多様な文字コードを処理
- 拡張されたRuby 1.9の文字関連処理
- スクリプトの文字コードの指定 マジックコメント
- Ruby 1.9の文字列
- 自分の符号化方式を知っている
- 文字列の連結
- Unicodeエスケープ
- 文字単位の操作
- 文字列の長さ
- Unicodeの結合文字やサロゲートの扱い
- 結合文字を含めた「1文字」をとる
- 入出力の符号化方式 IOクラス
- 入出力における文字コードの指定
- Encodingクラス
- Ruby 1.9のコード変換
- String#encodeメソッド
- 挙動の制御
- 変換できない文字の扱い 挙動の制御❶
- XMLのメタ文字のエスケープ 挙動の制御❷
- Encoding::Converterクラス
7.4 まとめ
第8章 はまりやすい落とし穴とその対処
8.1 トラブル調査の必須工具 ……16進ダンプツール
- データのバイト値を検査する
- od 16進ダンプのツール
- その他のツール hdxxd
8.2 文字化け
- 文字化けのよくあるパターン
- ラベルと本体の不一致による文字化け
- 機種依存文字に起因する文字化け
- 文字化け防止の原則
8.3 改行コード
- 改行コードに起因するトラブル
- 1つのファイル中の混在
- 想定外の改行コードの使用
- 改行コードの変換
- nkfコマンドによる改行コードの変換
- trコマンドによる対応
8.4 「全角・半角」問題
- 「全角・半角」で何が問題になるのか
- 問題の本質
- 区別のはじまり かつての機器のテキスト表示の制約条件
- 用語の本来の意味 印刷用語の全角・半角
- 文字コードは「全角・半角」を決めていない 1バイトの「A」2バイトの「A」
- 「(いわゆる)全角・半角」の存在は便利なのか
- 「全角・半角」問題への対応 利用者に「全角・半角」を意識させない
- 求められる文字入力プログラム 文字コードにおける一意な符号化という原則
- 入力文字の検証 アプリケーション側の対処法❶
- 重複符号化された文字の同一視 アプリケーション側の対処法❷
8.5 円記号問題
- 円記号問題とは何か
- ASCIIとJIS X 0201の違い
- 円記号問題の顕在化
- Webブラウザ上の表示
- Unicodeとの変換による問題 単なる表示上の問題では済まなくなる
- 対処のための注意点
- EUC-JPの場合
- 文字入力の際の注意
- チルダとオーバーラインについての注意
- 円記号問題は解決できるか
- 問題の本質 ``0x5C``の意味の違いを厳密に運用する
- 解決のための思考実験
8.6 波ダッシュ問題
- 波ダッシュ問題とは何か
- 現象の例
- 波ダッシュとは
- チルダとは
- 問題の原因 WAVE DASHとFULLWIDTH TILDE
- 変換の妥当性を検証する JISの1区33点とU+301Cの対応付け
- Unicodeの例示字形
- FULLWIDTH TILDEの存在
- Windowsの実装
- 変換の妥当性を検証する JISの1区33点とU+301Cの対応付け
- 三つの対処案
- ❶Unicodeに変換しない
- ❷コード変換を揃える
- ❸Unicode間で変換する
- 波ダッシュ以外の文字 変換による問題が発生しがちな文字
8.7 まとめ
Appendix
A.1 ISO/IEC 2022のもう少しだけ詳しい説明
- 符号化文字集合のバッファ
- 指示と呼び出し
- 94文字集合と96文字集合
- エスケープシーケンス
- 符号化方式の実際
- EUC-JP
- ISO-2022-JP
A.2 JIS X 0213の符号化方式
- 既存の資産を活かしつつJIS X 0213の利点を亨受するために
- 漢字用8ビット符号
- 適した用途
- EUC-JIS-2004
- 「国際基準版・漢字用8ビット符号」との関係
- 適した用途
- ISO-2022-JP-2004
- 包摂規準の変更による旧規格使用の制限
- 適した用途
- Shift_JIS-2004
- 適した用途
A.3 諸外国・地域の文字コード概説
- 中国 GB 2312とGB 18030
- GB 2312
- GB 18030
- 韓国 KS X 1001
- 北朝鮮 KPS 9566
- 台湾 Big5とCNS 11643
- Big5
- CNS 11643
- 香港 HKSCS
- ロシア KOI8-R
A.4 Unicodeの諸問題
- 正規化 いつのまにか別の文字に変わる?
- 問題
- 正規化
- NFKCNFKD
- 正規化によって別の文字に移される文字
- 日本語環境への影響
- 互換漢字の扱い
- Javaにおける正規化
- ファイル交換の際のトラブル
- 器問題 統合漢字と互換漢字の複雑な関係
- 拡張B 日本風台湾風の器器
- Webブラウザの表示例
- 異体字セレクタ 「正しい字体」への欲求
- 文字コードは文字の形を抽象化する
- 異体字を指定する
- IVS
- 互換漢字の代替手段としての異体字セレクタ
- プログラム上の対処
- 書字方向の制御によるファイル名の偽装
- 右から左に書く文字
- ファイル名の偽装
- 偽装のしくみ
- Windowsによる実験
- Windowsにおける対策
A.5 Unicodeの文字データベース ……UnicodeData.txtとUnihan Database
- UnicodeData.txt
- 文字の種別の判別
- Unihan Database
A.6 規格の入手・閲覧方法ならびに参考文献
- 参考文献